The Internet and the Web
“The internet is really, really great.”
Remember how we reviewed hypertext markup language (HTML) while we talked about remote servers? HTML is a foundational piece of the world wide web: a system of documents, the links between them, and the protocols for talking about them. Servers are the foundation of the Internet: the physical systems that combine disparate networks and which are responsible for facilitating communication between entities over the network.
Communication Networks
Before the Internet (circa 1983) people were communicating globally, albeit much, much, MUCH more slowly. This image from 1901 shows the telegraph cables running under the oceans between continents. Go back another hundred years and that same graphic could have represented shipping lanes.
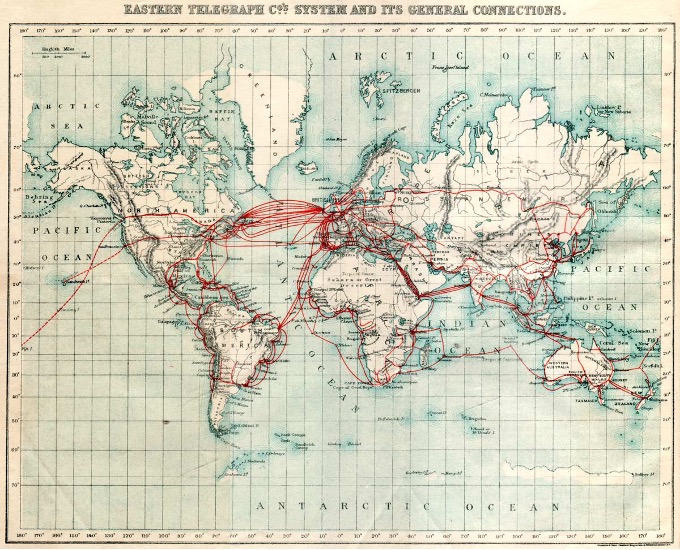
Technology has clearly sped that communication process up. Sending a message in the 1800s could take months and had to be done by hand. By 1900, telegraphs allowed messages to be sent without significant travel. And by the 2000s, the Internet allowed not just messages, but variety of data, images, audio, and video—all sent nearly instantaneously from a handheld computer.
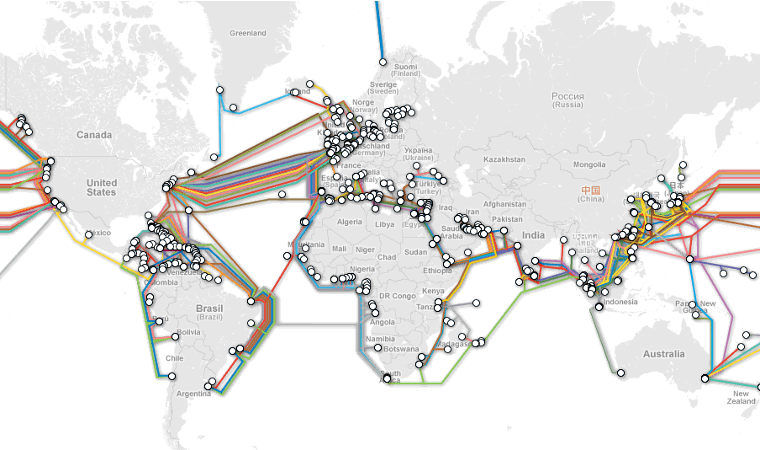
Every time a person or entity communicates over this network: information must be routed from the computer they start at, through a series of intermediate computers, then reaching a destination and starting the return trip. If Alexander was located in Bloomington, Indiana, USA and wanted to read content on the website associated with www.tu-darmstadt.de, then he would need to request the information before the website could respond with the information. Similar to how a written letter in the 1800s would pass from person to person, requests and responses between two computers must pass between computers and over wires.
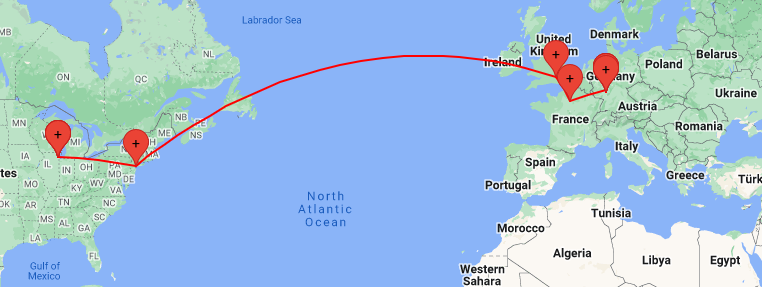
Addendum: traceroute
The
traceroutecommand (apt install traceroute) details which nodes and addresses sit between you and your destination.$ traceroute -I -q1 www.tu-darmstadt.de 1 hayesall (...) 2.571 ms ... 13 chi-b23-link.ip.twelve99.net (62.115.180.10) 18.726 ms 14 chi-bb2-link.ip.twelve99.net (62.115.126.158) 25.561 ms 15 nyk-bb2-link.ip.twelve99.net (62.115.132.134) 35.281 ms 16 ldn-bb1-link.ip.twelve99.net (62.115.113.21) 110.172 ms 17 prs-bb1-link.ip.twelve99.net (62.115.135.25) 119.136 ms 18 ffm-bb1-link.ip.twelve99.net (62.115.123.12) 120.602 ms ... 29 cms-sip02.hrz.tu-darmstadt.de (130.83.47.181) 130.942 ms
The Internet and the World Wide Web
What is the Internet then? The Internet is a series of connected computer networks with rules governing how computers on the network interact with one other.
The Internet is therefore an innovation in human communication. The physical and human infrastructure involved in that communication is no longer paper, hands, and ink: but system administrators, packets, and bits. This also means that when you overhear people complaining about “the Internet”—you can say to them: “Umm, technically, complaining about the Internet is like complaining about the postal service. You probably mean the world wide web.”
What is the world wide web then? It’s the interface, or the software running on servers connected to the Internet. The world wide web is what allows people to share information through links and through their interactions with web pages.
What we now call the world wide web (or www, but now often just called the web) was started by Tim Berners-Lee in 1989 at the European Organization for Nuclear Research (CERN). He originally referred to the project as the “Mesh”, and the “World Wide Web” terminology came about while actually writing the code.1 The reasons for creating the web were similar to the issues we used when motivating git: managing documents, sharing code, and preventing the loss of information. CERN followed a hierarchical tree structure (like we’ve seen on several different occasions): with engineers at the bottom, managers in the middle, and managers-of-managers at the top:
graph TB
C --- A;
C --- B;
A --- D;
A --- E;
Trees are excellent for organizing information—but hierarchies are a terrible way to organize people. Communication among people is network-structured. Have you previously worked somewhere? Did you have a boss? Was your boss the only person you ever communicated with?
The web, or “[t]he actual observed working structure” how people really communicate1 was Tim Berners-Lee’s answer to this problem, and it consisted of three key ideas:
- Hypertext (HTML). A means of representing content in an interconnected world. Documents written in a hypertext markup language could express arbitrary information, and would be discrete, referenceable nodes.
- Hyperlinks. A means of referencing or linking to other documents. Rather than following a tree structure: a link could reference anything, and a person following links could get to any document by following a chain of links back to the source.
- Hypertext Transfer Protocol (HTTP). A means of expressing actions over a network, such as getting a resource, posting a resource, or deleting something.
Perhaps more interesting is what the proposal left out. Hypertext is a means of representing information, not interpreting it, evaluating its relevance, or evaluating its truthfulness. Hyperlinks involve the name of a resource, but nothing about what to do when information changes. The protocol said nothing about security: the original assumption was that participants all knew and trusted each other (and secure HTTP—HTTPS—came many years later). We have hindsight—so more on those later.
Nevertheless, the most important thing was the generality of the three tools, and that good abstractions could be built on top of them. A person can be an observer to these three concepts. One does not even need to know what HTML, hyperlinks, or HTTP are. One can simply grasp the concept that they are looking at a document and following links—all while the protocol and servers work in the background to make it all possible:
graph LR
A --- B;
B --- C;
C --- A;
C --- D;
D --- E;
E --- C;
A --- E;
The very first web pages were written only in HTML and looked basic and were explored through command-line interfaces (CLI), but the concept of the web—connecting information with links—is still true today. The aforementioned abstractions turned into graphical user interfaces (GUI) browsers to help users navigate content.
The generality of pages, links, and protocols eventually meant the tools could be applied outside the niche interests of CERN, militaries, and governments—but would form an information infrastructure which could underlie everything else in the world.
Consider enrolling for classes in a world where the web does or does not exist:
- Before the web: enroll for class
- You can walk to Indiana University's registrar office, stand in line, talk to someone, request a paper bulletin, fill out a form with the class you want to take, drop off that form, and wait a week for the letter informing you that class is full.
- After the web: enroll for class
- You get Indiana University classes from the registrar's website. That website is connected to a database with real-time information about availability. You post a form telling the website which class you want.
Or consider traveling somewhere in a world with and without the web:
- Before the web: book a flight
- Flight information is scheduled and coordinated by airlines. You call an airline, or you solicit the services of a travel agent. The person you're talking with on the phone has a computer in front of them. That computer has a command-line application that helps them resolve your problem. You get a paper ticket mailed to you. If you lose the paper, you won't be allowed on the flight.
- After the web: book a flight
- You find a website that tracks flights from multiple airlines, and collates them according to price. You book a flight through an airlines website based on the time and price that works best for you. The ticket is a QR code stored in your phone.
The point, of course, is that many human problems are information problems. You want to do \(X\), but that first requires knowing about \(Y\), and informing another person or entity about your desire to do \(X\). Human hands, mouths, and minds can eventually move information information from one place to another: but an information system could instead be used to organize, access, and produce new information. Because an information system can fulfill these needs: many of the things that previously took hours, days, (or years) can instead be done in an instant.
Daily adult life, at least in a country like the United States, requires one to interact with interfaces to such information systems. Typically that interface comes via a website. Websites—the primary vehicle through which one accesses information on the web using the infrastructure of the internet—are therefore where we will concentrate for the rest of this book.
As Erika says: “Web interfaces are now the interfaces for our lives.” We’ve replaced checkbooks, paper forms, phone books, wall calendars, books, pens, paper, etc.. many of the physical items needed to run our households and manage our lives with web interfaces.
Programming concepts will not leave us: notice from our former examples that we had to look up information or sort results. The final website a user sees is like an iceberg: one will only see the 10% above the water. Our goal from this point forward is to see the whole iceberg: and build an information system.
Applications, or “apps”
But first, a brief diversion.
There were applications (now often shortened to apps) long before the web, and data storage predates computers by several millenia. That rock-paper-scissors implementation that we eventually called a “software package” evolved according to the same environmental pressures that made computers fundamental to daily life.
We started with a simple architecture: we asked for some user input, that input was translated into some internal “game logic”, and the product of the computer executing that logic was some output shown to the user.
graph LR
A[User Input] --> B[Game Logic];
B --> C[Show Output];
But we were unsatisfied with this mostly-stateless program. We wanted the program to also write, or store, its data to some location for later use.
graph LR
A[User Input] --> B[Game Logic];
B --> C[Show Output];
B -->|Write| D[File];
Finally we looped this data storage step back on itself. Not only could the application be affected by the user input: but problems like “showing a scoreboard” had to be based on external resources stored in files: meaning that program logic was now dictated by the present user input, but also the history of all past user inputs.
graph LR
A[User Input] --> B[Game Logic];
B --> C[Show Output];
B -->|Write| D[File];
D -->|Read| B;
This shows us that an application has three key components: an interface for input/output control, which drives the behavior of a back end implementing the logical core of the application, and a data store where application state is loaded from and saved to.
In rock-paper-scissors, we did not have a particularly clear demarcation between these three components. We implemented the application with a command-line interface where the input was a string, the internal states were predominantly managed with functions consuming and returning strings, and the output was (surprise!) a string printed to the console or saved to a file.
This approach to application design and information systems started around the 1890s with (what became) IBM tabulating the United States census. But like many human endeavors—the generality of the approach wasn’t recognized until many years later. And as we saw with Tim Berners-Lee’s pain points that led to him inventing the web: simple file input-output devices were not particularly helpful when it came to the challenges of networked human communication.
If only there were some way to link these two ideas: an “application” with a “decentralized networked interface”?
Not just a website, but a web application
Websites evolved. (And they continue to evolve: this story is not over, the web is younger than your instructors). (Oh great. Thanks for the reminder Alex. At least Erika knows what these emojis that stand for “old” mean ☎️ 💾 💽 📠 📼?)
Websites evolved from being simple HTML documents into the complex designs whose behaviors could mirror the needs of the information they were tasked with representing.
The sort of websites we previously covered still exist, but we now call them static sites. Here: static has two meanings. Its first meaning comes out of computer science jargon, where static refers to the case where an object has a fixed, unchanging size, and needs no context-specific information to reason about.2 If an HTML document is stored on a server as a static file, that file has a fixed size that can be measured in bytes. Computers are phenomenal when data are fixed and known: meaning that a website built from static files is scalable,3 and a static file server can handle tens-of-thousands (\(10e4\)) of concurrent users.
Static sites remain popular for content that changes relatively infrequently: such as personal websites, portfolios, blogs, or this book. The second meaning of static is to contrast the word dynamic. An object that is dynamic is either moving, or it is changing, or it is in some way responding to the world it inhabits. The time component in a dynamic equation. A dynamic site is therefore a site which is always in flux. Users can get information, but users can also change how the site behaves over the course of their interactions with it (like, post, subscribe, add, checkout, login).
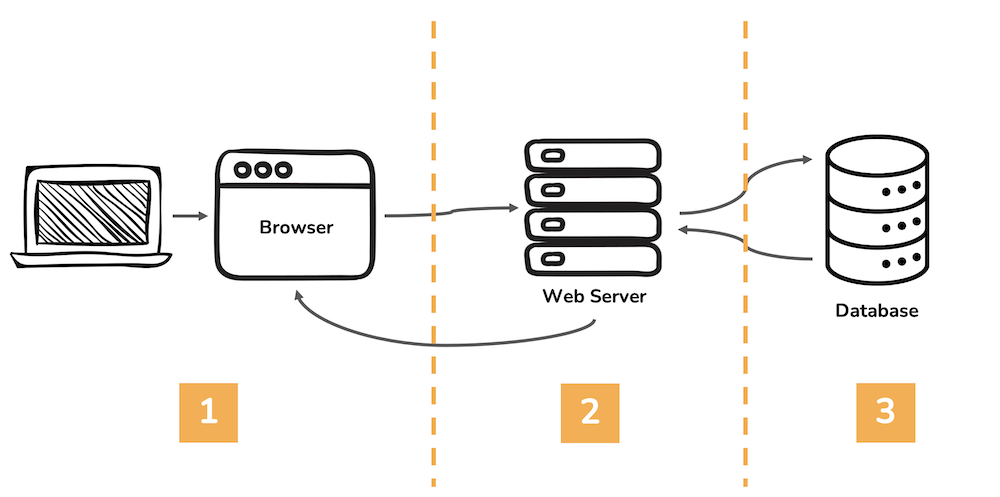
The three components that we said made up the web—HTML, hyperlinks, and HTTP—have little to say on how dynamic sites are built. But the basis for dynamic sites is buried within HTTP methods (or the HTTP verbs): GET or POST.
Web applications are made of three layers:
- An interface (frontend) - made of HTML, CSS and JS
- A framework (the control) - a programming language and an application framework, like Python/Flask - another popular combo you’ve probably heard of is JavaScript/React
- A database (backend) - we’ll be using MariaDB and SQL
In this unit, starting today, we’ll start with the interface and work our way through how to use the Flask framework. In the final unit, we will add in the backend.
The Request / Response Cycle
Because our interface is web-based, let’s first look at what happens after we type a URL into a browser and hit return:
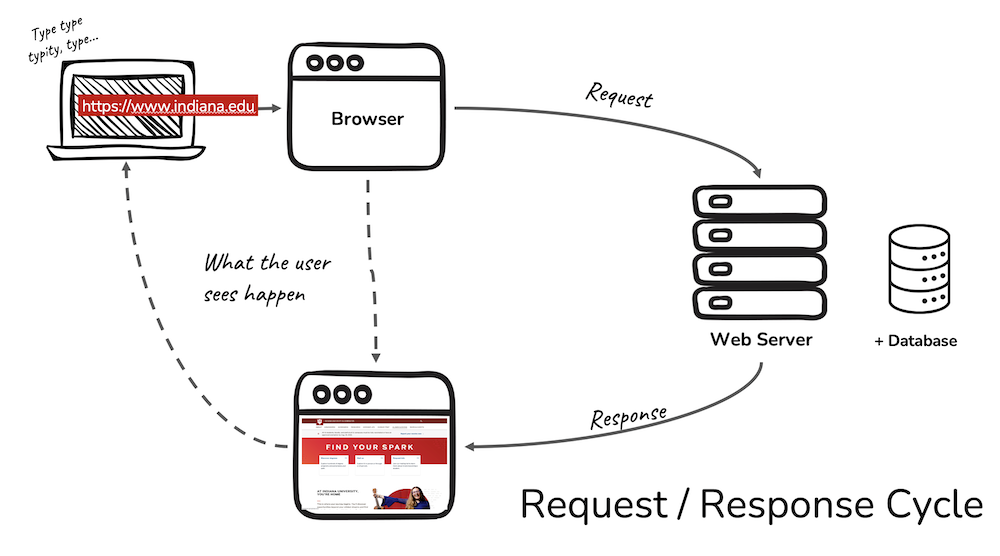
The user isn’t usually paying attention to what the browser is up to. A user’s main goal is to click a link or type in a URL and immediately access a web page with the desired information. A user MIGHT be vaguely aware that there is a web server (somewhere) (doing something) that the browser is connecting to.
What we as web application developers need to know is that when we click on a link, the browser initiates a two-step Request / Response Cycle in order to show you the linked page.
Using Your Browser as a Web Developer
- Watch the video to learn how to access the code behind the content in a web browser like a developer does. We’ll also take a look at how to see the request response cycle in action.
Step One: DNS
First, the browser uses the Internet to REQUEST the address for the URL submitted from a Domain Name Server (DNS). The URL is made up of friendly words, making it easier to remember and be understand by humans.
The DNS RESPONDS with an IP address (four sets of numbers separated by dots like this 129.79.7.128) based on the URL, telling the browser where to look on the Internet. Think of it as looking up a friend’s phone number in the Contacts on your phone. We maybe don’t remember the phone number, but we hopefully remember our friend’s name.
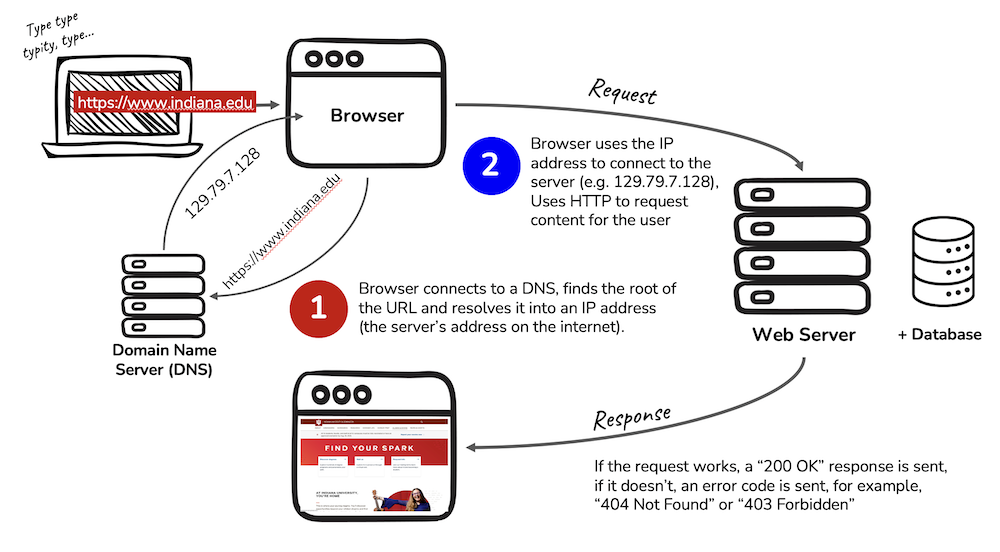
Step Two: Server
Second, the browser goes back out onto the Internet, now with an address in mind, to REQUEST data from a server (networked computer).
Once a connection has been made, the web server will RESPOND by sending the requested information in little packets of data until all of the data has been sent. As each resource for the web page come into the browser, a status code of 200 OK indicates the data was received.
Other possible status codes you might recognize are 404 Not Found and 403 Forbidden.
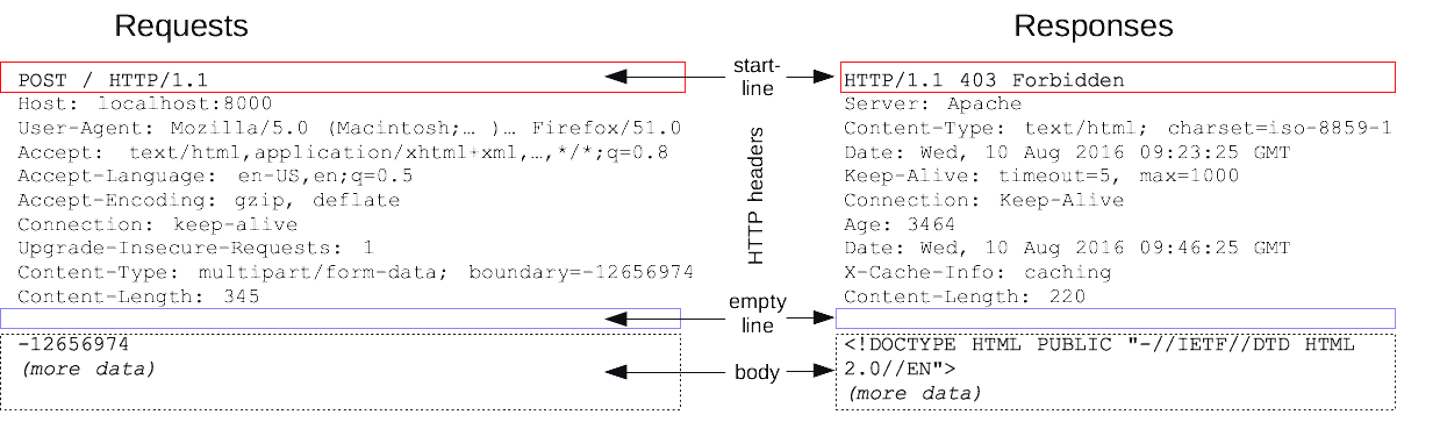
Assuming all goes well, the browser now takes any HTML, CSS, JS, images, etc.. sent from the web server and displays that content as a web page. And all of that happens in milliseconds.
The Request / Response cycle is fundamental to how browsers and the Internet (and later on, databases) interact. To see this interaction happening in the browser:
-
Open up the developer tools / web inspector in your browser. (how to do this)
-
Click the Network tab, then refresh the page to see a list of all of the requests and responses between the browser to the server. You’ll see columns of information showing the status code (most should say 200 OK), method used to send the data (GET is most common), and the domain (assets.iu.edu, or google, for example)
-
Scroll down in the list of requests/responses and click on one of the rows. You should information about the Header, Request and Response sent between the browser and web server.
Client-side versus Server-side
Let’s think about the second step - where the browser connects to the web server. There is a division here between technologies that work on the client-side and those on the server-side.
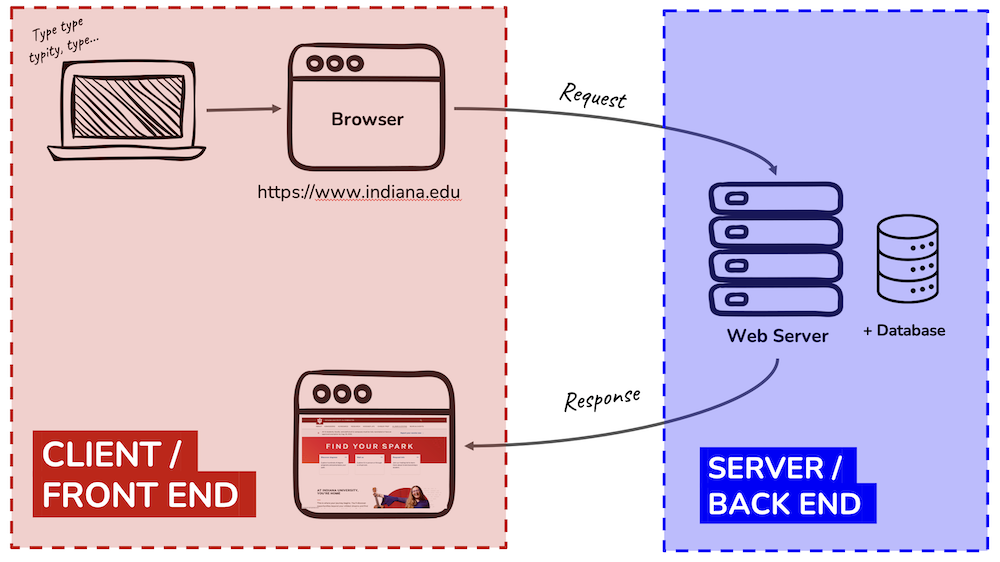
For each of the following, is this technology considered frontend (client-side) or backend (server-side)?
Make a guess before you reveal the answers.
- Python
- HTML
- CSS
- JavaScript
- SQL
- PHP
- Google Chrome Browser
- Apache Web Server
Technologies that work on the ‘frontend’
Frontend
HTML, CSS, JavaScript, and the Google Chrome Browser
Anything 'browser' like Firefox, Safari, etc.. is also here
Technologies that work on the ‘backend’
Backend
Python, SQL, PHP, and the Apache Web Server
Node.JS is a backend version of JavaScript, so if you put JS in this bucket, you are correct in that it can in a general sense do both
Anything 'server' (like Apache) or 'database' (SQL) related is here
Practice
Reminder from Networked Computers, Servers, and HTML: Websites about the structure for a simple website.
Set up
Continue to work out of your https://github.iu.edu/i211su2024/USERNAME-i211-starter today.
Note - your instructor is working just locally, no repo, the video was made before we had decided what repos to provide to you. So please work out of the same local repo you used for Rock Paper Scissors. You’ll be creating a folder for a simple static website today, and also a different folder for another static website tomorrow. You can run it locally (open the HTML files on your computer in a browser) to see what it looks like. No worries about pushing it to production or running on a web server. That’s what the end of this week will focus on when we start setting up Flask.
OK let’s go
Static websites have a simple tree-like data structure. Each item has only one parent, but that same item can have multiple children.
In HTML this structure is nested, with tags inside of tags. The outermost tag is <html>.
-
The
<head>contains information about a web page, along with resources such as CSS, fonts and sometimes JS. -
The
<body>is where all content we want to appear on screen lives, and is the more likely place for where JS lives. We want the HTML content to load and then the JS, so often you’ll find script tags at the very end of the BODY just before the close body tag.
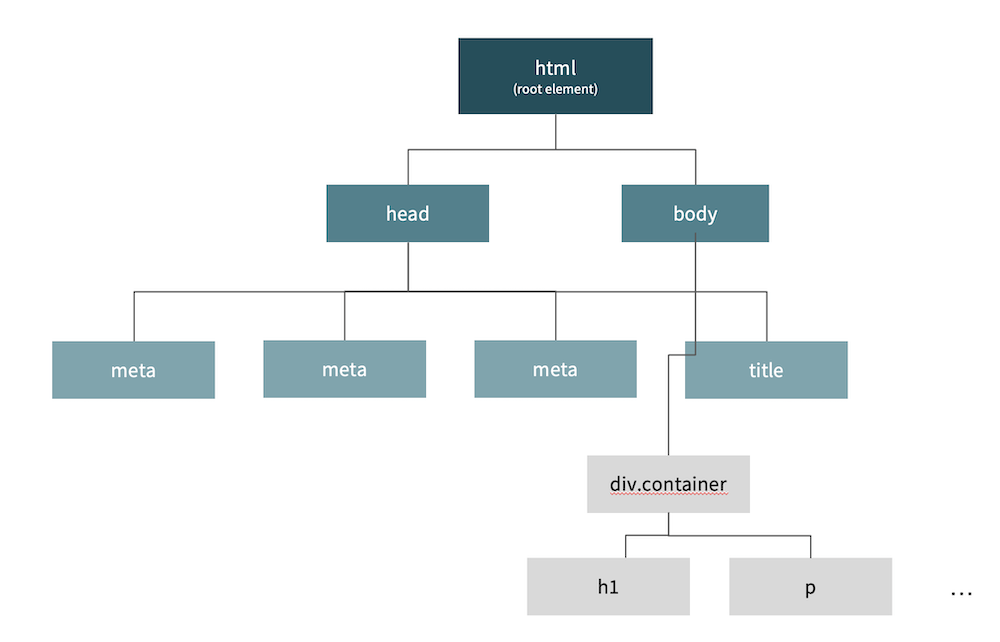
This image shows not only the required tags for an empty web page, but also where CSS, JS and other HTML should be placed.

We’re going to build a static website (locally) with the goal of seeing how the HTML, CSS and JavaScript fit together to form a web page.
Note: Although we will write a bit of CSS today, nearly all of the CSS and JS in i211 will be taken care of by Bootstrap, a frontend framework providing styles and layout through class attributes for HTML tags.
Follow Along with the Instructor
Work through the practice with the instructor! This video goes into much less detail than what is written in the book, however, we also spend time on tips for VS Code, for example. You need both resources, it’s not a choose one or the other situation. 🤔
Building a Static Website
At the command line, change into the directory where your i211-starter repo is located. Set up a directory for a static site. Then open the repository in VS Code.
cd USERNAME-i211-starter
mkdir static-site
cd static-site
code .
Using the “New File” and “New Folder” buttons in VS Code’s Explorer to create the following file structure. Begin by creating a directory and naming it static-site. Note that images, css and js are all folders; index.html and level-up.html will be empty at first.
static-site
├── index.html
├── level-up.html
└── images/
├── html-css-js.png
└── flask-logo.webp
└── css/
└── js/
Place these two images into your images folder (right-click and save):

![]()
Set up a home page
Let’s start with index.html, the home page.
- Open the Bootstrap documentation
- Under ‘Quick Start’, copy the code under Step 2 Include Bootstrap’s CSS and JS and paste this into
index.html. Make sure you save. - In VS Code, go to Extensions (fifth icon down on the left), then search for and click the green “Install” button to install Live Server by Ritwick Dey. (You won’t need to restart, go back to Explorer when done) You should now see “Go Live” in the bottom right of your VS Code window.
- Click “Go Live” - this will open a local webserver and display your page in your default browser. The page should say “Hello, world!”.
Live Server giving you trouble? You can also just navigate to the HTML page you made and double click on it within your operating system. It will open in your default browser. To see changes, however, you’ll need to refresh the page.
What are we looking at here?
The HTML code can be broken down into these distinct parts:
<!doctype html>
<html lang="en">
<head>...</head>
<body>...</body>
</html>
doctypetells the browser that this is modern HTML.htmltag to hold the pieces of the web page.
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap demo</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.3/dist/css/bootstrap.min.css" rel="stylesheet"
integrity="sha384-QWTKZyjpPEjISv5WaRU9OFeRpok6YctnYmDr5pNlyT2bRjXh0JMhjY6hW+ALEwIH" crossorigin="anonymous">
</head>
The head tag contains information and resources that are needed for the page, but do not appear in the browser window.
- sets character encoding to a universal character set
- page will make use of mobile design techniques
- sets a title to appear in a tab in the browser’s window
- links to Bootstrap’s CSS for styling and laying out content
<body>
<h1>Hello, world!</h1>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.3/dist/js/bootstrap.bundle.min.js"
integrity="sha384-YvpcrYf0tY3lHB60NNkmXc5s9fDVZLESaAA55NDzOxhy9GkcIdslK1eN7N6jIeHz"
crossorigin="anonymous"></script>
</body>
The body tag contains all content displaying on the web page, plus a spot for any JavaScript needed for page interactions.
h1tag is a top-level headline used as the main title for a web page- JS is included in a
scripttag, and is always at the bottom of thebodytag, right before the tag closes. This link pulls in Bootstrap’s JS resources.
Add structure, content and an image to the home page
Let’s add some structure.
The main requirement for structuring a page is that your content needs to be inside a container controlling the width and position of the content.
- Open Bootstrap’s documentation under Layout for adding a container
- Copy the code for a default container, and place these tags around the
h1
<div class="container">
<!-- place H1 here -->
</div>
Now add an image to the home page.
- Open Bootstrap’s documentation for how to add images
- Copy the code for a “responsive image” - this means the image will expand and contact in size to accommodate wider and narrower viewports
<img src="..." class="img-fluid" alt="...">
- Paste this HTML underneath the
h1tag (inside of the container) - Anytime you see
...in Bootstrap, it means “add your stuff here”:- For
src, type inimages/html-css-js.png- we need a relative link meaning the path is from where the index.html page is to where the image we want is located. - For
alt, add a short description or name for the image, for example, “logos for html css and js.” This attribute is required for accessibility.
- For
Make sure you check your progress in the browser.
Link to another page
Next let’s add a link to the page, either a standard link or one that looks like a button:
<!-- ADD a text-based link -->
<a href="#">Level Up!</a>
<!-- OR make it look like a button -->
<a class="btn btn-primary" href="#" role="button">Level Up!</a>
- To make the link work, replace the hashsign
#in the HREF with the path to the nearby HTML filelevel-up.html.
Time to add some style to the content.
Take a look at Bootstrap’s documentation as you add these so you can understand how to apply the code from their examples to our project.
- Add Spacing: Push the content away from the top of the page by adding the class
mt-5 - Center some text: Center the headline on the page with the class
text-center - Center an image: Center an image on the page with the classes
d-block mx-auto - To center the button, place it inside a DIV and use
text-center.
<div class="container mt-5">
<h1 class="text-center">Hello, world!</h1>
<img src="images/html-css-js.png" class="img-fluid d-block mx-auto" alt="logos for html css and js">
<div class="text-center">
<a class="btn btn-primary" href="level-up.html" role="button">Level Up!</a>
</div>
</div>
Make a second page
Finally, add a second page. A website isn’t much of a website if it doesn’t link pages together!
Repeat the process above on level-up.html to add an H1 and an image.
This time:
- H1 says “Level Up!”
- Image is set to
flask-logo.webp - Link directs to Flask’s documentation (https://flask.palletsprojects.com/en/3.0.x/)
Once again, make sure you check your progress in the browser.
Summary
We created a simple, static website using Bootstrap. Things to notice:
- The CSS and JS folders are empty!
Using Bootstrap means we don’t need to add our own CSS or JS unless we want to add custom styles or interactions.
- The HREF in a link is different for pages INSIDE and OUTSIDE of the site.
Linking to a page in my site means using a relative link - one that is based off where the HTML file lives in the file structure. Whereas an external link needs the whole kit and caboodle (the full URL including “https://”).
- The
level-up.htmlpage has a hyphen in the filename!
In HTML, the filenames often end up in the URL, thus names with multiple words are separated by DASHES. (In Python, we use underscores. This stylistic difference can be annoying to remember, but will ultimately help us tell the difference between code for the front-end and code for the programming or database portions of our web app.)
Footnotes
Berners-Lee, Timothy J. (1989). “Information Management: A Proposal (No. CERN-DD-89-001-OC).” Online. Accessed 2023-06-13. https://www.w3.org/History/1989/proposal.html
This is the static in public static void main.
Without diving into computational complexity theory: an algorithm is scalable when adding one additional computer provides one additional unit of work—without severe diminishing returns.