PyMySQL and Flask II
The remaining routes in our Flask application are related to tags. Let’s begin by updating database.py. To start, we need to:
- Create a table called
taggedin the database to hold tag data - Use Python to load data from
tagged.csvinto thetaggedtable - Write a function to get all tagged data, and one to get all tags for a specific recipe
Try each of these steps on your own, checking against the solutions only after you’ve tried it.
Follow Along with the Instructor
Practice with the instructor. Not an exact replacement for the written directions. Read the text below this first before proceeding.
- Set up tagged/tags in the database.
1. Create a “tagged” data table
The first step is to update database.py to include a data table for the tagged.csv instead of a CSV.
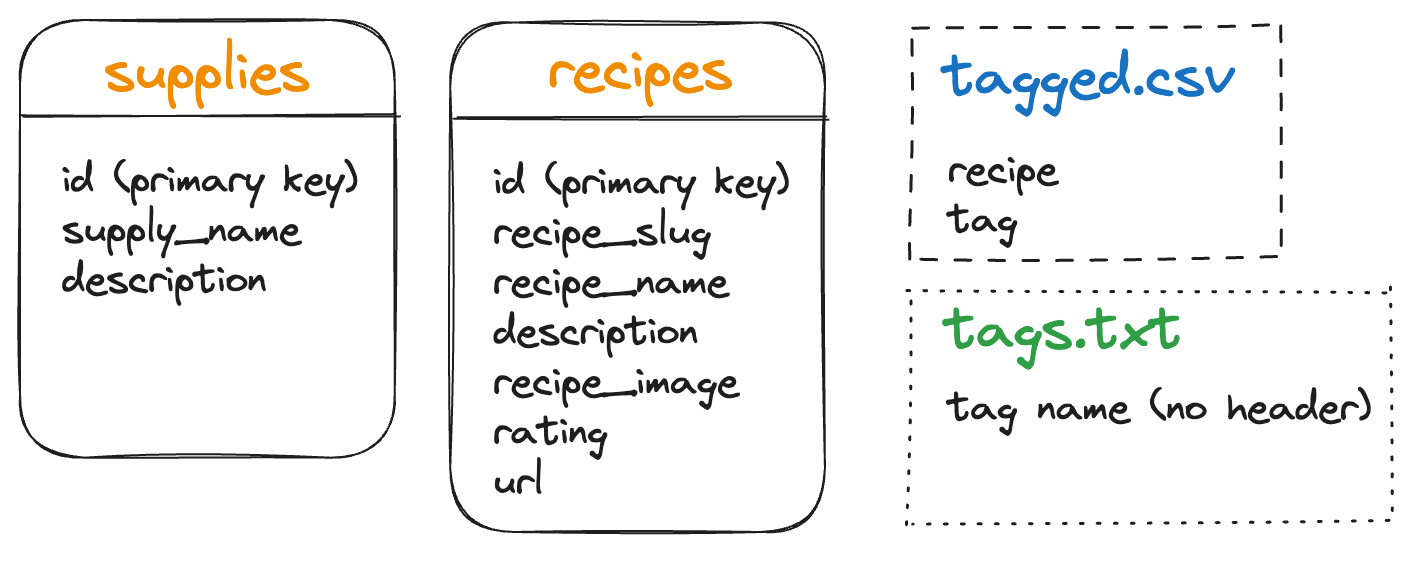
We know we need:
- integer as the primary key for the
id(our unique identifier)
Looking at tagged.csv to see what other attributes and datatypes to include we see:
- recipe (currently the recipe’s slug)
- tag
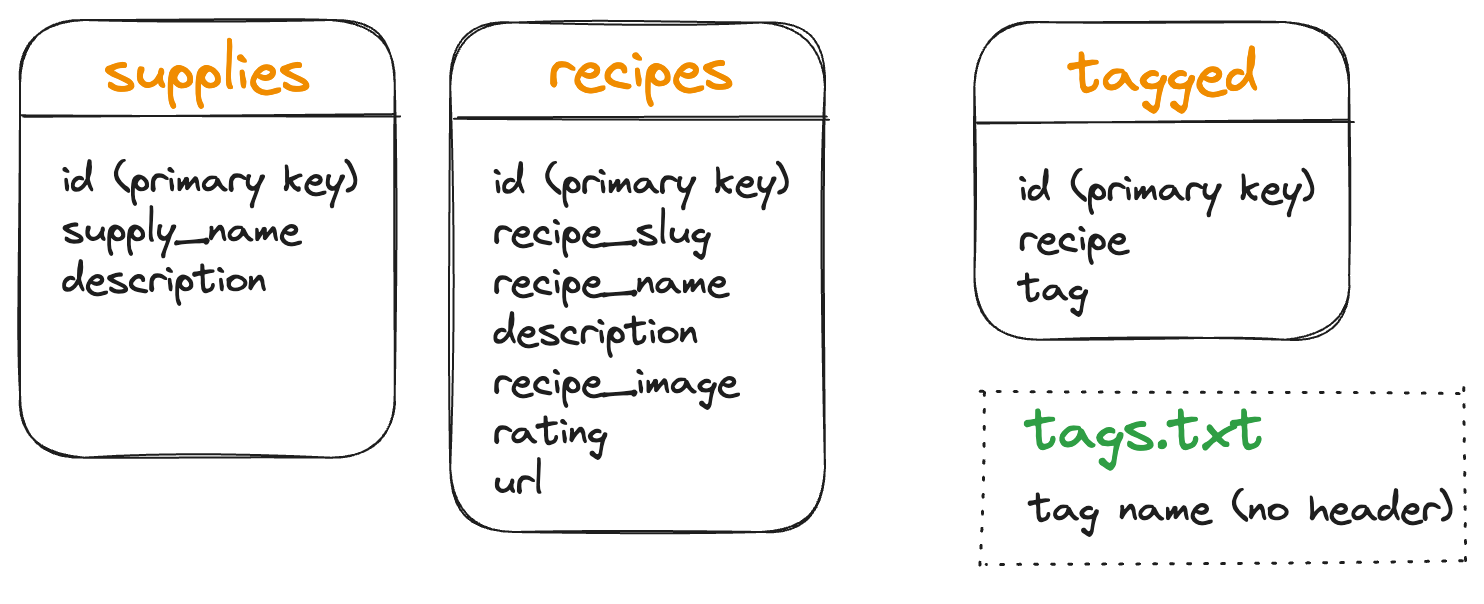
Just because the CSV was set up a certain way DOES NOT MEAN that the database should be the same. Because we now have a relational database, it makes sense to connect to the full recipe record in the recipes table – to establish a relationship.
Caveat: there are many ways to structure data and design a database. Whole courses exist to teach you just this. The choices made here are deemed most instructional for THIS course.
Connect tables using a foreign key
When we connect one table to another, that is indicated by a foreign key or the reference ID from another table.
CREATE TABLE tagged (
...,
constraint `fk_recipe_id`
foreign key (recipe_id) references recipes(id),
) engine=InnoDB;
To set recipe_id as the foreign key we set a constraint and give it a name. One convention is to call this fk_<attribute> meaning “foreign key for the specified attribute”. We then set the foreign key to be an attribute in our current data table, and list what attribute the key will reference in another table.
- One more time 😅: this says constraint “fk_recipe_id” is a foreign key called “recipe_id” and its value is an id from the “recipes” data table.
Instead of a column of recipe names in slug form, we now have a column with a unique id pointing to the record for a recipe.
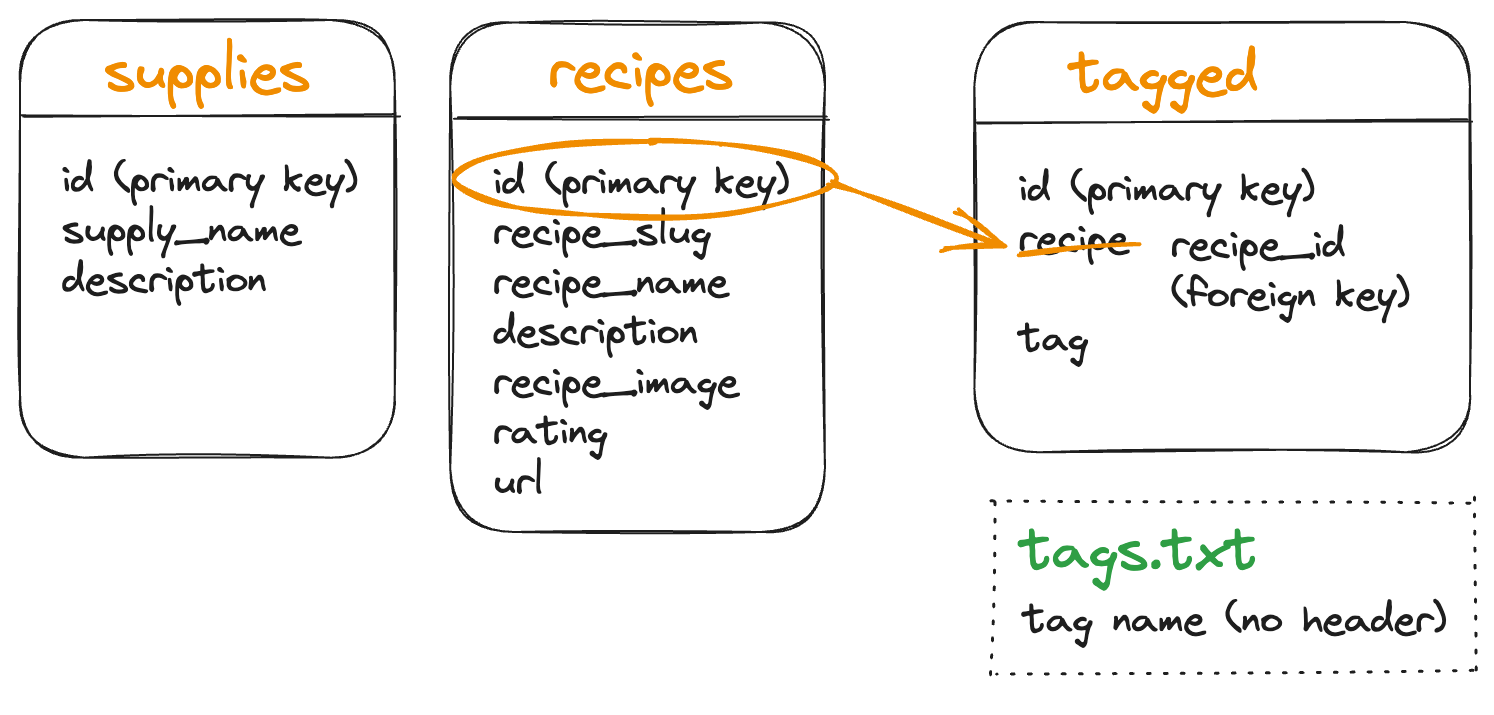
We can now eliminate the “tags.txt” file
We also have a text file listing all of the possible tags. Again, because this information will be stored in the database, it makes the most sense to simply pull in all tags in tagged to create a list of tags.
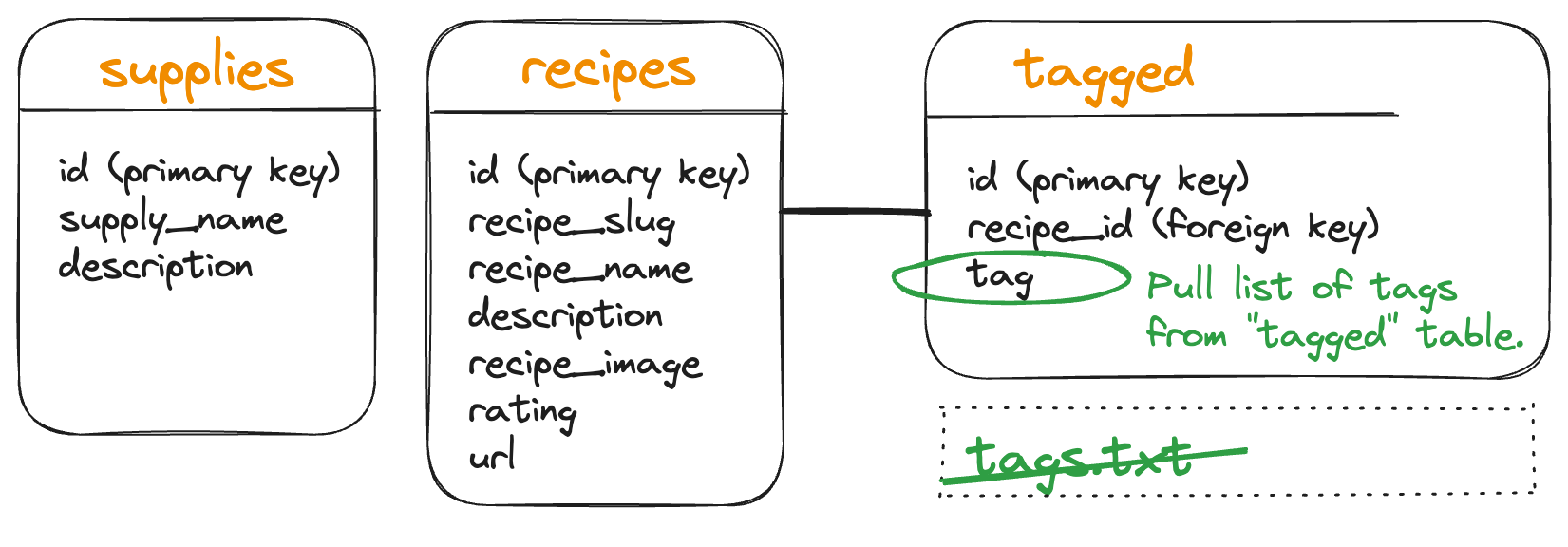
(Depending on future plans for the tags, a table could be created just to hold those possibly tag names. We don’t plan to go further with this app, so this choice finishes our database design and eliminates the need for CSVs and TXT files beyond the inital loading of some data.)
Possible Solution for Adding the Tagged Table
def initialize_db():
...
_tagged = """
create table tagged (
id int auto_increment primary key,
recipe_id int,
tag varchar(25),
constraint `fk_recipe_id`
foreign key (recipe_id) references recipes(id)
) engine=InnoDB
"""
Note: We MUST DROP THE TAGGED TABLE FIRST. This is because the foreign key is linked to the recipes table. That dependency will keep the “drop table” command from executing, so easiest is just to drop “tagged” first.
Possible Solution for Adding the Tagged Table Continued...
def initialize_db():
...
with conn.cursor() as curr:
curr.execute("drop table if exists tagged")
curr.execute("drop table if exists supplies")
curr.execute("drop table if exists recipes")
curr.execute(_supplies)
curr.execute(_recipes)
curr.execute(_tagged)
conn.commit()
conn.close()
2. Load CSV data into the “tagged” table
We made changes to how the data is structured, so we’ll need to adjust our initial data to match if we still want to bring in the “tagged” data from the CSV.
Update “tagged.csv”
Replace the current text in tagged.csv with the following. Instead of a “recipe” holding a slug, we now have a “recipe_id” holding the ID for the recipe that appears in the “recipes” data table.
recipe_id,tag
1,vegetarian
1,cheese
1,breakfast
4,pasta
4,vegetarian
5,vegetarian
6,vegetarian
6,drinks
6,breakfast
3,rice
10,rice
Once the tagged.csv files is updated, let’s continue to update database.py.
Pull the data from “tagged.csv” into our database
Use Python and PyMySQL to pull the data out of tagged.csv and insert it into the tagged data table. This includes opening the CSV and looping through the available records…
Possible Solution for Pulling in Data from Tagged CSV
if __name__ == "__main__":
initialize_db()
...
with open("tagged.csv") as csvf:
for tagged in csv.DictReader(csvf):
add_tagged(tagged)
…as well as writing a function to help you add each row of data to the data table.
Possible Solution for Adding Data to Tagged Table
def add_tagged(tagged: dict[str, str]) -> None:
conn = get_connection()
with conn.cursor() as curr:
curr.execute(
"insert into tagged (recipe_id, tag) values (%s, %s)",
(
tagged["recipe_id"],
tagged["tag"],
),
)
conn.commit()
conn.close()
The INSERT is referencing the attributes in the new CSV file.
Re-initialize our database
Re-run the database.py file and re-initalize the tables, initial data in the tables, and set up the functions we’ll be using inside our app. See PyMySQL and Flask 1 for details.
Remember, this will delete any data we had updated in the app, so we won’t want to initialize everything again once our app is in production. Designing, planning and implementing a database is something that should be done with care. Once we begin to use the database, it becomes much harder to make adjustments. 😓 For this lecture repo, we’re just starting over each time we make a change.
Follow Along with the Instructor
Practice with the instructor. Not an exact replacement for the written directions. Read the text below this first before proceeding.
- Set up helpful function to access tags in the database
- Refactored the index route to handle tags
3. Write a function to get all data from the “tagged” table
To best access this tagged data, we should to be able to:
- grab the contents of the entire “tagged” data table
- make a specific selection to get the tags applied to an individual recipe
- select all of the tags in use
We can take this one step further and translate this need into pseudo code.
Update database.py by writing the following functions:
get_all_tagged()to select all of the records from thetaggedtableget_tags(recipe_id)to select the tags applied to the recipe indicated by the idget_all_tags()to select all of the tags present in the tagged table
Get all tagged recipes:
Possible Solution for a Function to "Get All Tagged" Recipes
def get_all_tagged():
conn = get_connection()
with conn.cursor() as curr:
curr.execute("SELECT * FROM tagged")
all_tagged = curr.fetchall()
conn.commit()
conn.close()
return all_tagged
Get all tags for a single recipe:
Possible Solution for a Function to "Get Tags" for a Recipe
def get_tags(recipe_id):
conn = get_connection()
with conn.cursor() as curr:
curr.execute("SELECT * FROM tagged WHERE recipe_id = %s", (recipe_id))
tags = curr.fetchall()
conn.commit()
conn.close()
return tags
Get all tags in use:
For get_all_tags() we have options.
We can say SELECT tag FROM tagged; and get all of the tags in the data table, however, this includes duplicate tags, which we have quite a few of.
- Option 1: Using Python in
app.pywe could then filter those tags into a list of unique tags. - Option 2: We can use the SQL keyword “DISTINCT” and that will limit our selection.
SELECT DISTINCT tags FROM tagged;
You may implement whichever way makes the most sense to you.
Possible Solution for a Function to "Get All Tags" Currently Used
def get_all_tags():
conn = get_connection()
with conn.cursor() as curr:
curr.execute("SELECT DISTINCT tag FROM tagged")
all_tags = curr.fetchall()
conn.commit()
conn.close()
return all_tags
Updating the tagging system in our application
Now we switch over to app.py to make use of all our hard work on the database and in PyMySQL.
In each of these routes, do not copy and paste this code in. Instead find where there are changes between your current code and the code we provide below, then adjust line by line as needed.
We really want you to see where changes need to be made and (eventually) how much simpler the code will now read without the mess caused by trying to use a CSV as our only data source.
Update / route
The data coming back from db.get_all_tagged() is a list of dictionaries:
[{'id': 1, 'recipe_id': 1, 'tag': 'vegetarian'}, {'id': 2, 'recipe_id': 1, 'tag': 'cheese'}, {'id': 3, 'recipe_id': 1, 'tag': 'breakfast'}, {'id': 4, 'recipe_id': 4, 'tag': 'pasta'}, {'id': 5, 'recipe_id': 4, 'tag': 'vegetarian'}, {'id': 6, 'recipe_id': 5, 'tag': 'vegetarian'}, {'id': 7, 'recipe_id': 6, 'tag': 'vegetarian'}, {'id': 8, 'recipe_id': 6, 'tag': 'drinks'}, {'id': 9, 'recipe_id': 6, 'tag': 'breakfast'}, {'id': 10, 'recipe_id': 3, 'tag': 'rice'}, {'id': 11, 'recipe_id': 10, 'tag': 'rice'}]
But it’s more helpful to us if it is organized as a dictionary where the key is the recipe_id and the value is a list of all tags assigned to that recipe:
{1: ['cheese', 'breakfast'], 4: ['vegetarian'], 5: [], 6: ['drinks', 'breakfast'], 3: [], 10: []}
To do this, it’s helpful to write a function:
def make_tags_by_recipe(all_tagged: list[dict]) -> dict[list]:
tags_by_recipe = {}
for tagged in all_tagged:
if tagged['recipe_id'] in tags_by_recipe.keys():
tags_by_recipe[tagged['recipe_id']].append(tagged['tag'])
else:
tags_by_recipe[tagged['recipe_id']] = []
return tags_by_recipe
This allows us to simplify the code in our route:
@app.route("/")
def render_index():
all_recipes = db.get_recipes()
all_tagged = db.get_all_tagged()
tags_by_recipe = make_tags_by_recipe(all_tagged)
return render_template("index.html",
all_recipes=all_recipes,
tags_by_recipe=tags_by_recipe
)
Code that changed in the “index.html” template:
...
{% for tag in tags_by_recipe[recipe['id']] %}
<span class="badge rounded-pill text-bg-success">{{ tag }}</span>
{% endfor %}
Follow Along with the Instructor
Practice with the instructor. Not an exact replacement for the written directions. Read the text below this first before proceeding.
- Update the recipes/recipe_id and add tag routes.
- Complete the lecture application, including deploying.
Update /recipes/<recipe_id> route
Two updates to the data here, tagged_as to show which tags the recipe has, and all_tags which populates the dropdown in the form to add a new tag.
tagged_as
For tagged_as, we want to use db.get_tags(recipe_id) to get all the tags the current recipe has applied. The format in this case is fine, and we can use jinja to unpack it in “recipe.html”:
[{'id': 1, 'recipe_id': 1, 'tag': 'vegetarian'}, {'id': 2, 'recipe_id': 1, 'tag': 'cheese'}, {'id': 3, 'recipe_id': 1, 'tag': 'breakfast'}]
Code that changes in “recipe.html” template:
{% for tag in tagged_as %}
<span class="badge rounded-pill text-bg-success">{{tag['tag']}}</span>
{% endfor %}
all_tags
The dropdown on “recipe.html” needs a simple list of tags, yet we see that when we call db.get_all_tags(), it’s currently a list of dictionaries.
[{'tag': 'vegetarian'}, {'tag': 'cheese'}, {'tag': 'breakfast'}, {'tag': 'pasta'}, {'tag': 'drinks'}, {'tag': 'rice'}]
Putting just the tag names into a list will do the trick.
def make_clean_tags(all_tags: list[dict]) -> list:
return [tag['tag'] for tag in all_tags]
['breakfast', 'cheese', 'drinks', 'pasta', 'rice', 'vegetarian']
Using a helper function makes our route’s function a little simpler too. If you’re not familiar with list comprehensions, the code in make_clean_tags is the same as saying:
clean_tags = []
for tag in all_tags:
clean_tags.append(tag['tag'])
Sorting those tags in place gives us a nice way to send the data on to the template where it’s displayed in a dropdown menu.
Updated recipe route
@app.route("/recipes/<recipe_id>")
def render_recipe(recipe_id="None"):
one_recipe = db.get_recipe(recipe_id)
one_recipe['rating'] = '⭐️ ' * int(one_recipe['rating'])
all_tags = make_clean_tags(db.get_all_tags())
return render_template('recipe.html',
one_recipe=one_recipe,
tagged_as=db.get_tags(recipe_id),
all_tags=sorted(all_tags)
)
Update /api/tags/<recipe_id>/add route
The code here changes quite a bit, and is for the most part simpler because we now have specific functions in database.py handling the needed selections.
@app.route("/api/tags/<recipe_id>/add", methods=["POST"])
def add_tag_to_recipe(recipe_id: str):
added_tag = request.form["tag_name"]
if not added_tag:
return "Bad request, missing tag name", 400
if not recipe_id:
return "Bad request, missing recipe", 400
if not db.get_recipe(recipe_id):
return "Bad request, unknown recipe", 400
# need way to keep out duplicates
db.add_tagged(
{
"recipe_id": recipe_id,
"tag": added_tag
}
)
return redirect(url_for("render_recipe", recipe_id=recipe_id))
We’re also going to adjust the forms in “recipe.html” to handle the adjustment to the add_tag_to_recipe route, and the recipe’s id being passed along.
<form action="{{ url_for('add_tag_to_recipe', recipe_id=one_recipe['id']) }}" method="POST" class="row g-3 my-4">
Validating the tags
Right now, if we want to add a tag “fancy” and we want to add it again, there is nothing stopping us! 🎩 Additionally, there is no check on whether the tag the user came up with even SHOULD be added.
The first part - duplicates - is a straightforward fix:
if the tag is NOT present in the "tagged" table for THIS recipe:
# add tag to tagged data table
else:
# send along an error message to appear in the template
See if you can write this condition.
That second part is a harder problem that we’d need to think about. Do tags get reviewed and approved by a person? Is there a set of guidelines for what will be accepted? Or perhaps it doesn’t matter; it’s any tag goes. This is a case of us not thinking through how the site will be used and how that impacts the data needs.
We’re here at the end of our development for the recipe site though, so those are all future problems 🔮 to consider more strongly in your next application.
We don’t need the helper function anymore?
Now that we’ve used that “make_clean_tags” helper function twice, and we’re at the end of our app’s spec, we might now know that we just always need that list-of-dictionaries format. Should we determine that is what we want everytime that data is pulled, we could delete the make_clean_tags helper function and all references to it in app.py and instead add the reorganization step to the get_all_tags function in database.py:
def get_all_tags():
...
# clean up the tags to be a list
return [tag['tag'] for tag in all_tags]
This is totally optional to do today.
Functions we can now delete in app.py
In app.py we can delete the functions we used to work with CSVs!!! 😮
- import csv
- get_all_recipes()
- tbr(all_tagged)
- get_all_supplies()
- get_tags()
- csv_to_tbr()
- set_all_recipes(all_recipes)
- tbr_to_csv(tbr: dict[str, set[str]])
- register_new_tag(tag_name: str)
Your app.py should now look dramatically cleaner, clearer and more manageable.
Time to Wash the Dishes? 🍽️
We’re at the end of our build for 🍳 Make This Now!. You created a modern, fullstack web application! We’ve spent a lot of time “cooking. Are you hungry 🤤?
(In terms of the amount of work we put in for this small site with limited data, you might be questioning whether it even qualifies for a fullstack application treatment! 🤨)
A site with A LOT OF DATA or A LOT OF PAGES is really going to benefit from all this structure (and we did need to start somewhere). So if we need a site to be able to “scale” this is what we mean – a site with a structure that can handle 5 pages, but also scale to 5000.