How Language Works
4 Word forms: processes
In the last chapter, we looked at the basic units that make up the forms of words in spoken language: syllables and the consonants and vowels that combine to form syllables. In this chapter, we will look at various ways in which these units may change. First, a given phoneme may be pronounced differently depending on the phonemes that immediately precede and follow it. Though processes like this seem to originate in making it easier for Speakers to produce sequences of phones, they become conventional. That is, different languages make use of different processes of this sort. These kinds of processes also depend on the formality of language; in casual speech, there are often additional simplifications to the forms. Second, the units of linguistic form obviously change through the course of language learning. A beginning first or second language learner does a poor job of producing and recognizing the units of the target language but gets closer to the capability of a native Speaker/Hearer as learning progresses. Finally, the units of linguistic form change more slowly throughout the entire community of Speakers/Hearers. That is, the phonological conventions that define the forms of any language are not constant. In this chapter, we will also review much of what we've covered concerning linguistic form in the context of different English accents.
4.1 |
Phonetic contexts |
Lexical and phonological knowledge
I've been claiming that the sounds of a human language are clustered into categories called phonemes. As a speaker of English, then, what do you have to know to be able to pronounce an English word, say, the word fun? Hint: some of what you know is about just that word and some of what you know is more general.
The main point of what I said about the sounds of spoken language in the last chapter was to show what phonemes are. Let's review this concept.
- They are specific to particular spoken languages (or dialects actually); that is, learning a language means in part learning the phonemes of the language.
- They are categories,
with all of the familiar properties that
categories have.
- Phonemes are realized as individual sounds (phones), instances of the categories, that may differ from one another but are centered on a prototypical member. That is, a phoneme is not really a phone, but an abstraction over a collection of phones.
- Phonemes divide a continuous space (one or more continuous dimensions) into a small set of types.
- Individual phones are categorized by hearers as belonging to one or another of the phonemes of the hearers' language. Phones that are closer to the prototypical member are easier to categorize. Phones that are within a phoneme are perceived as closer to each other than phones that belong to different phonemes, even when the real difference is the same (categorical perception).
- Phonemes provide a kind of "alphabet" in terms of which speakers and hearers remember the pronunciations of words.
Let's focus on the last point for now. I tried to argue in the section on phonemes that phonemes provide a more efficient way of remembering a large number of words than the alternative. How might this memory system work? We'll concentrate on what the Speaker has to remember. Let's take the English word fun, which we assume is stored in the Speaker's (and the Hearer's) memory as the sequence of phonemes that we have been writing as /fʌn/. (Of course the claim is not that anything like these symbols is written in the person's brain, only that there is some representation of the three phoneme categories and their order.)
Now how would the Speaker use this representation in memory to actually pronounce the word fun? Another sort of knowledge is needed: knowledge about how each phoneme is realized in terms of articulation. So for /f/ the Speaker would need to know to bring the lower lip in contact with the upper teeth and pass air through the opening without vibration of the vocal cords. And for /ʌ/ the Speaker would need to know to open the mouth a certain extent and raise the body of the tongue somewhat while causing the vocal cords to vibrate. Finally for /n/ the Speaker would need to know to bring the tongue tip in contact with the alveolar ridge, to lower the velum, and again to cause the vocal cords to vibrate.
I'll refer to this knowledge about how phonemes are produced as realization rules. This is our first use of the term rule, which you'll meet a lot later in this book. It refers to general knowledge about what to do in a particular kind of situation. Notice how this differs from the way the word rule is used outside of social science; realization rules are learned but not taught, and speakers are not conscious of the rules they know. And calling the knowledge a "rule" should not make us think that it takes the form of some sort of explicit statement in the brain of the Speaker. In fact little is known about the precise form that rules take; this is currently an area of great controversy in cognitive science.
Just as the Speaker needs to know how to produce each phoneme, the Hearer (who of course is also a Speaker) needs comparable knowledge for how to perceive each phoneme, knowledge about what the phonemes sound like. However, since I have had little to say about the acoustic or auditory properties of phonemes, I'm not in a position to spell out in more detail what this knowledge is.
The two kinds of knowledge, knowledge about the form of a particular word in terms of a sequence of phonemes and knowledge about how particular phonemes are articulated or recognized, differ in one very important way. Knowledge about the form of particular words must be memorized for each word; none of this is general knowledge. This knowledge belongs in the lexicon, the storehouse of knowledge about particular words. On the other hand, knowledge about how phonemes are produced or perceived is general; it applies to all words containing the phonemes. This knowledge is part of the Speaker's and Hearer's phonology, that is, general knowledge about the form that words can take in the language. The figure below illustrates these two types of knowledge.
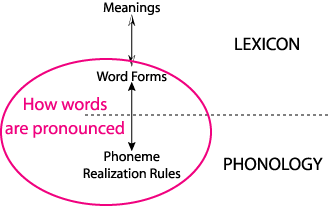
The fact that phonological knowledge is general means that it applies to other words as well. For example, the word laugh /læf/ also contains the phoneme /f/, so the realization rule for /f/ applies to this word as well. And the word no /no/ also contains the phoneme /n/, so the realization rule for /n/ applies here too. These examples are illustrated in the figure below. The arrows below the phonemes indicate that each phoneme gets spelled out as a set of articulatory actions and an auditory pattern. The arrows all go in both directions because the knowledge has to be usable by both speakers (down in the figure) and hearers (up in the figure).
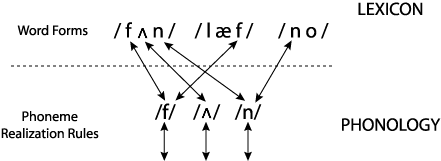
The same would hold true for other languages, except that the phonemes would be different (so the knowledge about how they are produced and perceived would be different), and of course the words would also be different.
Realization rules may also specify how combinations of phonemes are pronounced. One confusing area in English is the behavior of the sonorants /m, n, ŋ, l, r/ in unstressed syllables, in words like prizm (/m/), happen (/n/), incredible (/ŋ, l/), under (/r/). One possibility is to see these in each case as a vowel, /ə/ or /ɪ/, followed by one of the sonorant consonants. So prizm is /'prɪzəm/, and incredible is /ɪŋ'krɛdəbəl/. But, as we saw in the section on English sonorants, the unstressed vowel is sometimes not pronounced; instead the sonorant is syllabic, behaving almost like a vowel. Sometimes this is the only natural pronunciation; sometimes it depends on the speed and informality of the situation. So a relatively casual pronunciation of incredible is [ŋ̩'krɛdəbl̩] (recall that a short line under a consonant symbol indicates a syllabic consonant). Since this knowledge about how to realize combinations like /əl/ is general knowledge about English, we can put it in the realization rules in the phonological component.
Phonemes in context
Listen to the sound represented by the letter "t" in the word put in the following sentences.
- Put something on.
- Put me down.
- Put it on the table.
- Put this on.
- Put your shirt on.
If you listen carefully, you may hear as many as five different "t" sounds. What does this mean? Should we assume that English speakers have five different phonemes in place of the single /t/ that we discussed in the section on English consonants? Keep in mind what phonemes are and what function they serve in language.
But the picture is not this simple. Remember point 2a about phonemes above: the actual instances of a given phoneme will differ from one another. So one /f/ will not necessarily be the same as another /f/. But are the differences just random? Let's consider /t/, where the variations are quite striking. Take the word at, which in terms of the phonemes that have been proposed would be represented in the lexicon as /æt/. Given what we've said so far about English /t/, the realization rule for this phoneme would have to include specifications that the speaker place the tip of the tongue against the alveolar ridge and produce the sound without vibration of the vocal cords. (The specification is intentionally somewhat vague about how the consonant is released so that it can apply to /t/ at both the beginnings and the ends of syllables.)
This works fine for the /t/ in at when the word appears before a word beginning with /f/ (at four o'clock) or /s/ (at six o'clock), say. But when it appears before a word beginning with /θ/ (at three o'clock), and we say it in a natural way, we see that the tongue tip is not against the alveolar ridge, but against the teeth, as for a dental stop ([t̪]). And when it appears before a vowel (at eight o'clock), the consonant, as pronounced by North Americans anyway, is voiced and articulated as a tap rather than a stop. In fact it is very similar to the Spanish /r/, that is, the phone that is more accurately represented in our notation by [ɾ]. So we see that not only does the final consonant in at take different forms, there is a regularity to the forms it takes; the pronunciation depends on what phoneme follows that consonant.
How are we to deal with this kind of variability in our theory of how the pronunciation of words is represented? One possibility would be multiple representations of the word at in the lexicon: /æt/, /æt̪/, /æɾ/. Since we would now be using /t̪/ and /ɾ/ to represent words in the lexicon, these would have to be seen as English phonemes, in addition to /t/. But note that this wouldn't be enough; a list of different pronunciations of the word would have to say something about when each one was appropriate, for example, use /æɾ/ when the next word begins with a vowel. And of course the phonological component of memory would need to specify how /t̪/ and /ɾ/ are produced and perceived, as well as /t/.
But this would be a strange way for language to work. Why should speakers be forced to remember more than one form for a word? The whole point of phonemes (at least that is what I'm trying to argue) is to make words easy to remember. Recall also that the lexicon is supposed to be for knowledge about specific words, not general knowledge about how words are pronounced. If the information about different ways to pronounce at applies to more than just the pronunciation of at, then it does not belong in the lexicon; it belongs in the phonological component. If we examine a lot of English words, we discover that many of them (for example, put and let, as illustrated in the box above) end in consonants that behave exactly like the consonant at the end of at. In each case the different pronunciations of that consonant depend on the first phoneme in the next word.
So now consider a second alternative. The lexicon records only one pronunciation of at, /æt/, and the phonological component specifies how the /t/ is to be pronounced (or perceived). The difference from the simple picture described in the last subsection is that this specification has to refer to what comes after the /t/. So it would include something like the following: if /t/ is followed by a dental fricative, place the tongue against the upper teeth, and a corresponding statement for each of the other variant pronunciations. Now the realization rule for /t/ is really a set of rules, one for each type of following phone and the corresponding realization of /t/. The different realizations of a phoneme are called its allophones. We'll come back later to a more detailed statement of what the realization rules and allophones for English /t/ are. For now, there are these important points to note.
- An allophone is always an allophone of some phoneme; it makes no sense to say simply that a particular phone is an allophone in a language. So in English we've seen that [t], [t̪], and [ɾ] are all allophones of the English phoneme /t/.
- This sort of knowledge about how a phoneme is realized as different allophones is general knowledge that speakers have about English, not about particular English words. It is in fact part of the knowledge of what the different English phonemes are.
- The different ways in which a phoneme such as /t/ is pronounced, that is, the allophones of /t/, are similar. They differ at most in one or two features from each other. In fact /t/ is a rather extreme example for English; a phoneme such as /f/ varies relatively little.
- The realization of the phoneme pronounced as one or another allophone usually depends on what other sounds are near the phoneme in question, that is, on the phonetic context of the phoneme. In the section on assimilation, we'll learn more about how contexts determine allophones, and in the section on distribution, we'll learn about how you can use the different contexts that phones appear in to decide whether they're allophones of a single phoneme or separate phonemes.
- Allophones are not categories. This means that speakers and hearers do not need to categorize the different allophones of English /t/. The only category they need among these variants is /t/. It also means that hearers may not even notice the difference between the different allophones of a phoneme. As far as they are concerned, they all belong to the same category. This fact is often reflected in writing systems, which almost never assign different characters to different allophones of a phoneme. So English uses a single letter "t" for all of the allophones of the phoneme /t/.
Let's look at a Spanish example of the same phenomenon. Consider the word de 'of, from'. If we listen to this word spoken in isolation or at the beginning of a sentence, for example in the expression de nada 'don't mention it', we would conclude that its form consists of the two Spanish phonemes /d/ and /e/. As in the English example above, the actual pronunciation of the word would require knowledge about how /d/ and /e/ are articulated, that is, realization rules for these phonemes. This is a different language, so the realization rules would not be the same as for the English phonemes that we write with /d/ and /e/. Thus Spanish /d/ is a dental, not an alveolar, stop ([d̪]), but the basic principle still applies: phonological knowledge is general; it applies to many words.
But consider now how the word de sounds when it appears in a phrase following a vowel, for example, in un vaso de leche 'a glass of milk'. Here the consonant in de involves no complete closure between the tongue and upper teeth, so this is not a stop. Some people refer to this sound as a fricative, but since the closure is usually not close enough to allow for any of the turbulence associated with fricatives, it's better seen as an approximant. However, since the difference won't matter for our purposes, I'll use the same symbol that was used for the English voiced dental fricative, [ð], for this sound.
As in the example of English /t/, we need to ask whether this variability in the initial consonant is a special property of the word de or whether it's true of Spanish words in general. A brief examination of words containing the voiced dental stop ([d̪]) and the voiced dental approximant ([ð]) in Spanish reveals that this is a general feature of Spanish phonology. So the word de has one form in the lexicon, /de/, and the phonological component spells out how /d/ is realized in terms of specific articulations in different phonetic contexts, that is, as different allophones. Here is rough statement of how Spanish /d/ is pronounced.
- When /d/ appears at the beginning of a word following a break, or when it appears following /n/ or /l/, it is pronounced as the voiced dental stop [d̪].
- Otherwise /d/ is pronounced as the voiced dental approximant [ð].
The Spanish example should make two more points clear. First, the relevant context for determining how a phoneme is pronounced can be before as well as after the phoneme in question. Second, the sort of general knowledge about how phonemes are pronounced is specific to particular languages; it is general within the language, but it is not general enough to apply to all languages. We can see this by looking at the English phonemes /t/, /d/, and /ð/, and the Spanish phonemes /d/ and /r/. The English phoneme /t/ can be realized as [ɾ], but in Spanish, /t/ (dental, not alveolar as in English) and /r/ (pronounced as [ɾ]) are separate phonemes. Spanish /t/ is never voiced and never pronounced as a tap. The Spanish phoneme /d/ can be realized as [ɾ], but in English /d/ (alveolar, not dental as in Spanish) and /ɾ/ (always a dental fricative) are separate phonemes. English /d/ is never pronounced as a fricative or approximant.
However, as we will see in the next section, the rules that specify how phonemes in a given language are to be produced or perceived in different contexts are not completely arbitrary. There are good reasons for all of the rules, and, although almost none of them are universal, we can expect many of them to turn up in multiple languages.
Problems
4.2 |
Assimilation |
Anticipatory assimilation
The syllable un- means roughly 'not' in a word like unhappy, in which it is pronounced [ʌn]. Say the following words beginning with this syllable rapidly, and listen to how the nasal consonant in the syllable is pronounced: unbelievable, unpretentious, unkind, ungrateful. Assuming they did not sound like [n], what pattern do you notice in how the pronunciation of the nasal consonant depends on the following consonant?
Why would a phoneme have multiple realizations (allophones) in different contexts? Let's start with a simple example, the realization of /t/ as a dental, rather than an alveolar, stop, that is, as [t̪]. We saw this happening when /t/ comes before a dental fricative, for example, the first /t/ in at the top. Compare your pronunciation of this phrase with what it would be like if you pronounced the /t/ as an alveolar stop. (I'm assuming the alveolar prounciation is the prototypical articulation for /t/ because it's the most common place of articulation for this consonant.) You would have to slide your tongue forward from the alveolar ridge to the upper teeth as you go from the /t/ to the dental fricative /ð/ in the. It is simply easier to put the tongue behind the teeth for both the stop and the fricative.
This is illustrated in the figure below. The lines labeled "tongue tip contact" and "voicing" represent the relative timing of the articulatory actions that are required for the production of the sequence /æ/, /t/, /ð/ at the beginning of the phrase at the top. The two lines at the top illustrate the positions of the tongue for the two possible ways of pronouncing the sequence. The top line shows the movements for the normal pronunciation with a dental stop, [t̪]. The second line shows the movements that would be necessary if the /t/ were alveolar instead. There is an extra movement of the tongue tip to the alveolar ridge before it moves to the front teeth. That is, pronouncing the /t/ this way involves more movements.
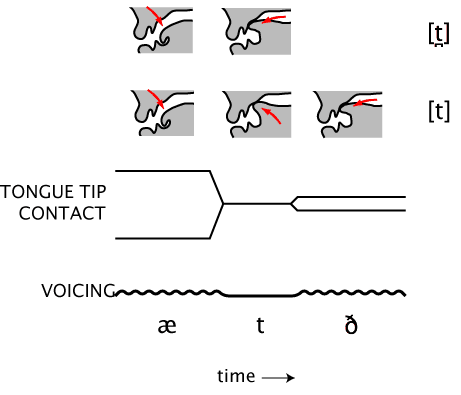
If the first stop in at the top is really an example of the phoneme /t/, we need an account for why this stop isn't produced in the prototypical way in this word. In this case the speaker anticipates the place of articulation (dental) of the following fricative. For English /t/ this appears to be quite general. That is, if we examine a lot of English words, looking for voiceless alveolar stops, we'll see that, in unaffected speech anyway, they don't occur right before dental fricatives. Instead they're replaced in that context by voiceless dental stops. The generalization holds not only for cases where the fricative following the /t/ comes in a separate word, as in at the top, but also when both phones are in the same word. One example is in the word eighth. Note that in this case the /t/ is not reflected in the spelling, but it is there, at least in my accent. Another example is the /t/ in width (spelled "d").
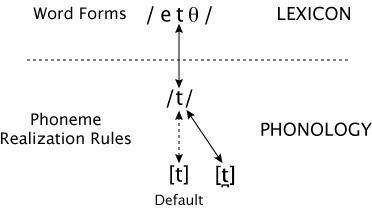
How do we represent words like eighth and width in the lexicon? The stops in these words are a little different from the stop in at because they are always pronounced as dental stops (in natural speech anyway). But it's easy to see why this is so: they are always followed by a dental fricative. So, just as with at, we will represent these words in the lexicon using /t/, and a realization rule in the phonological component will specify that the /t/ is realized as a dental rather than an alveolar stop. So the phonemic representation of eighth (in my accent) is /etθ/, and a more detailed phonetic representation showing the place of articulation of the /t/ (and the diphthongization of the /e/) would be [eɪt̪θ]. Likewise, the phonemic representation of width (in my accent) is /wɪtθ/, and the detailed phonetic representation is [wɪt̪θ].
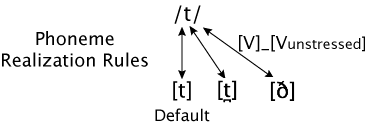
This is illustrated in the figure below. The prototypical pronunciation of /t/ is shown in bold and designated the "default", that is, the allophone that is used unless there is some reason to use another allophone. The arrow connecting the phoneme to the default allophone is dashed in the figure to indicate that it isn't the one used for this word.
But what we see with /t/ is even more general in English. Consider the /n/ in on the top and the /d/ in hide the money. In both cases, the natural articulation is dental, rather than alveolar. If we take the prototypical articulation of /t/, /d/, and /n/ to be alveolar, we can see what is going on here as a change or process: the prototypical articulation is modified when the phoneme is realized in a particular context. So the realization rules for English can include the general rule:
- Alveolar stops and nasals become dental when they precede a dental fricative.
The figure below illustrates the rule for /t/ only. The label on the arrow connecting the phoneme to its dental allophone means that that allophone is appropriate when the phoneme occurs before a dental consonant. The "_" represents the position of the phoneme, that is, directly before the dental consonant.
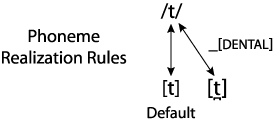
This rule makes sense because it makes articulation easier; one phone, the alveolar stop or nasal, agrees with another, the dental fricative. A process in which one phone comes to agree with one or more others in its context is called assimilation. Assimilation is a Speaker-oriented process because it makes articulation easier. But notice that the change from an alveolar to a dental consonant should not interfere seriously with comprehension because the resulting sounds are quite similar to the original ones and because English has no dental stop or dental nasal phonemes that could be confused with the sounds that result. In simplifying things for the Speaker, a Speaker-oriented process should not make things too difficult for the Hearer.
Let's look at an example with vowels. Listen carefully to the vowels in the following words as you produce them: tad, tan; sag, sang; jab, jam.
The vowels in the first word in each pair are probably not quite the same as those in the second word in each pair. The vowels in tan, sang, and jam are normally nasalized; that is, the velum is lowered during the production of these vowels, allowing air to pass through the nasal cavity as well as the oral cavity. But this makes sense because it is what will be required for the following nasal consonant (/n/, /ŋ/, /m/) in each case. The speaker anticipates the nasal articulation of the consonant during the production of the vowel. It is of course possible to keep the velum up during the vowel and then simultaneously make the oral closure and lower the velum for the consonant, but it is apparently easier to get the velum lowering out of the way during the relatively long vowel production. This avoids the need to perfectly coordinate the lowering of the velum with the contact in the oral cavity (bilabial for /m/, alveolar for /n/, velar for /ŋ/).
Note that the nasalization of the vowel in tan, sang, and jam is completely predictable from the vowel's context, specifically, the following nasal consonant. This means that there is no need to record the vowel's nasalization in the lexicon; this is a general property of the phoneme /æ/. So jam is /jæm/ in the lexicon, and a realization rule specifies that the /æ/ should be nasal because a nasal consonant follows.
This rule is illustrated in the figure below. [~] above the vowel symbol is used to indicate nasalization. As before there is a label on one of the realization arrows indicating the context for the rule, in this case, before a nasal consonant.
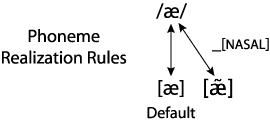
Not surprisingly the same holds in English for other vowels, though how much the velum is lowered depends on the particular vowel. We can include something like the following in the phonological component for English:
- Vowels tend to be nasalized when they precede nasal consonants.
We can illustrate this more general rule as in the figure below. Here "V" means any English vowel.
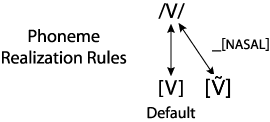
This means that all English vowels have a nasalized (at least to some degree) allophone, which occurs when the vowels precede a nasal consonant. As before, this Speaker-oriented process should not interfere too seriously with comprehension; Hearers should have no difficulty recognizing the phonemes for the nasalized vowels.
Perseverative assimilation
One rapid, informal pronunciation of the word something is ['sʌmʔm̩]. (Recall that [m̩] indicates a syllabic nasal). Why do you think the final nasal, [ŋ] in the careful pronunciation in many accents, has become [m]?
In the examples we've seen so far, the assimilation is anticipatory; a phoneme changes its pronunciation in order to agree with a following phone on some dimension. Assimilation can work in the other direction as well. Let's look at Spanish /d/ again. Recall that this has an approximant allophone, [ð], when it follows any phone other than /n/ or /l/. For Spanish the only other possible previous phones are the others that can end a syllable: vowels, semivowels (/w/, /y/), /r/, /s/, or another /d/ (realized as the approximant). None of these is a stop; that is, there is no complete and sustained closure of the oral cavity (for /r/, a tap, there is a rapid closure followed by a release). Following any of these phones, pronouncing the /d/ as a stop would interrupt the open oral cavity. The approximant [ð] preserves this opening, and in this sense it is an example of assimilation: the consonant takes on one of the features of the previous phone (in the case of /r/ it is the open state of the oral cavity following the tap itself ). In this case the assimilation is perseverative; a feature of one phone "perseveres" during a following phone.
The figure below illustrates this Spanish rule, though just for the case where /d/ follows a vowel. In this case, the "_" symbol follows the relevant context ("vowel") because it is what precedes /d/ that determines which allophone to use.
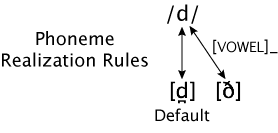
But why wouldn't this happen when the /d/ follows /n/ or /l/? Note that both of these Spanish consonants do involve contact of the tip of the tongue with the teeth, precisely the place where the stop [d̪] has its contact. Thus in these cases pronouncing the /d/ as the approximant would involve releasing the contact that has already been made for the previous consonant. So it makes some sense that /d/ does not change its manner of articulation in these contexts.
As with the English assimilation of alveolar to dental place of articulation, this process in Spanish applies more generally than to just /d/. Let's look at what happens to words beginning with voiced bilabial stops and voiced velar stops. I'll use the symbols [β] and [γ] to represent voiced bilabial and velar approximants.
- blanco, caballo blanco
- gordo, caballo gordo
In these examples, [b] occurs when the phone appears at the beginning of a word following a pause, and [β] occurs when the phone follows a vowel. Similarly, for [g] and [γ], the stop occurs following a pause and the approximant occurs following a vowel. This is exactly what we saw with /d/, so it appears that Spanish also has /b/ and /g/ phonemes, each with (at least) two allophones and that a general rule applies to change the default stop manner of articulation to approximant manner of articulation when the phoneme follows a vowel.
However, unlike for /d/, /b/ and /g/ also become approximants following /l/, as in these examples:
- el blanco
- el gordo
Why would /d/ remain a stop following /l/ while /b/ and /g/ become approximants? Recall that the behavior or /d/ following /l/ made sense because the tongue makes contact with the teeth for /l/ as it does for the dental stop [d̪]. But the articulator for [b] is the lips and for [g] the back of the tongue (making contact with the velar region of the roof of the mouth). Since neither of these gaps is closed during the production of /l/, leaving them open for a following /b/ or /g/ would represent the same sort of perseverative assimilation we see when these consonants follow vowels.
That leaves the situation with /b/ and /g/ following nasal consonants, which is a bit more complicated and more interesting. I will leave it for one of the problems for this section.
Let's look at one more English example, another of the allophones of English /t/, which illustrates both perseverative and anticipatory assimilation. But before we consider /t/, let's look at one of the allophones of English /d/. Listen to what happens to the [d] in do when it is preceded by a vowel and not stressed.
- How do we go?
- Who do you like?
- Why do I think that?
When do is pronounced in isolation, it starts with a stop, but when it follows a vowel and is not stressed, the [d] becomes a tap. The difference is not very great since there is still a contact at the alveolar ridge (as well as voicing), but the contact in the case of the tap is made by a quick gesture of the tongue tip and the contact is very brief. If we look at a lot of English words, we see that this is generally true for North American English /d/. For example, /d/ is pronounced like a tap in words like rider, muddy, and needed. The realization rule is something like the following:
- When /d/ begins an unstressed syllable, follows a vowel, and precedes a vowel (including /ər/ but excluding [n̩] and [l̩], that is, the variants of /ən/ and /əl/ without the vowel), it is realized as a tap ([ɾ]).
Why might this be? Though we probably cannot call it assimilation because the oral cavity is open before and after the consonant and closed as the consonant is produced, this does appear to be a Speaker-oriented process. To pronounce the /d/ like a stop, the tongue tip must make contact with the alveolar ridge and remain there for some time. For the tap articulation, it must only make brief contact with the alveolar ridge. Thus in general the tap appears to be easier to execute in this environment.
Now let's consider /t/ in the same context. We already saw in the section on contexts that /t/ may also be realized as a voiced tap. We saw this with the word at, but we can also see it in the middle of words such as butter, city, and Italy. If the default (prototypical) pronunciation of /t/ is as a voiceless stop, there are two changes here: the /t/ becomes a tap and it becomes voiced as well. We have just seen (for /d/) how pronouncing a stop as a tap when it comes between two vowels may simplify articulation for the speaker. The voicing of the /t/ is an example of assimilation. Both the phone before and the phone after the /t/ in these words are voiced, so allowing the voicing to continue through the articulation of the /t/ simplifies matters somewhat for the speaker. Because the assimilation points in both directions, it is both perseverative and anticipatory. The figure below illustrates this process. It shows the third allophone of /t/ that we have seen, [R], and an indication of the context where it is used. The "_" appears between two vowels ("V"), the second of which is unstressed.
While assimilation makes good sense from the perspective of the Speaker, we can't use it in general to predict how phonemes in different languages will behave. First, particular assimilation rules that operate in one language or dialect may not operate in another. For example, English does not have a rule like the Spanish rule that causes voiced stops to become approximants (although something like this may happen in English in very rapid, casual speech), and in most English accents /t/ is not voiced when it comes between vowels as it is in North American accents. In other words, there is an arbitrary aspect to assimilation; which kinds of assimilation apply to a particular language and dialect must be learned. Second, some of the allophonic variation that is exhibited by phonemes seems to have nothing to do with assimilation. We will see examples of this type next.
Non-assimilative allophonic variation
Let's go back once more to the most complicated consonant in English, /t/. Compare the /t/ in till with the /t/ in still. As described when we discussed consonant voicing and voice onset time, the /t/ in till is aspirated. That is, there is a significant lag between the release of the contact and the beginning of voicing, and you can feel a puff of air being expelled during this lag. To show this detailed pronunciation, we can write [th]. But note that this is not the way the /t/ in still is pronounced. For this sound the release and the beginning of voicing roughly coincide.
But why not treat these two kinds of t-sounds as two different phonemes? Recall once again that different phonemes are used to distinguish words from one another. Can these two kinds of English t-sounds distinguish words from each other? If we could have the aspirated t ([th]) in a word like still, then we could have one word pronounced [stɪl] (with unaspirated t) and another word pronounced [sthɪl] (with aspirated t). But the aspirated sound never appears in this position, and if it did (and this is important), English hearers would still hear the word as still. The same would be true if we used the unaspirated sound in the word till. English hearers would still hear the word as till, or perhaps as dill, but not as some other word with neither /t/ nor /d/ at the beginning.
So it seems that the distinction between [t] and [th] cannot be used in English to distinguish one word from another. Since these two sounds are very similar to each other and they cannot be used to distinguish words from each other, we conclude that they belong to the same phoneme, that they are both allophones of /t/. But notice that the realization of /t/ as (unaspirated) [t] or (aspirated) [th] is a regular phenomenon, something that English speakers know how to do. This means that we need realization rules in the phonological component telling when [t] is appropriate and when [th] is appropriate. Here's a stab at what they would look like.
- When /t/ appears at the beginning of a stressed syllable, it is aspirated. (The details of its pronunciation depend on what follows it.)
- Otherwise /t/ is unaspirated. (The details of its pronunciation depend on what precedes and what follows it.)
But we can be even more general than this. Consider the words pot and spot. The /p/ sounds in the words show exactly the same alternatives as the /t/ sounds in till and still. And the same is true for the /k/ sounds in the words car and scar. If we examine a lot of words containing /p/ and /k/, we see that the alternation is just as general as it is for /t/. So the realization rule can apply to all three phonemes:
- When a voiceless stop appears at the beginning of a stressed syllable, it is aspirated.
- Otherwise a voiceless stop is unaspirated.
It is usually not surprising for English speakers to learn that the [th] in till and the [t] in still belong to the same category. In fact they probably were not even aware that there were these two different sounds, and some English speakers cannot hear the difference even after it is described to them. The difference between these two allophones of /t/ in one sense doesn't matter for English in the way that the difference between /t/ and /d/ does matter. English hearers do not have to identify a sound as being [t] or [th] because what they care about is what words they are hearing, and the difference between these two sounds never matters for the words. However, they do have to identify a sound as being /t/ or /d/ because it can make a difference, say, between till and dill or between bat and bad. Learning English apparently includes learning to emphasize the differences between sounds such as [t] and [d] and de-emphasize the differences between sounds such as [t] and [th].
But why would these English stops behave this way? These are not examples of assimilation: the /t/ in stop cannot be said to agree with the /s/ that precedes it or the /ɑ/ that follows it any more than it would if it were aspirated. If we view the unaspirated stops as the default (prototypical) allophone, then why would these stops get aspirated when they come at the beginning of stressed syllables? The origin of this process is probably more Hearer-oriented than Speaker-oriented. For the Hearer, what matters is that /t/ sounds different enough from nearby phonemes, namely, /d/ and /θ/. In terms of voice-onset time, [th] is further from [d] than [t] is, especially at the beginning of a syllable. The gap between the release and voicing is longer, and there is the (possibly audible) puff of breath. Since aspiration requires more breath, it is easier to achieve in stressed syllables, which are executed with a greater effort. Thus English has settled on a set of realization rules for voiceless stops that maximize the distinctions between voiced and voiceless stops at the beginning of stressed syllables.
Note, however, that in some other contexts, the distinction between voiced and voiceless stops disappears altogether in English. Following an /s/ in the same syllable, only voiceless stops are possible; that is, there are no words like /sdɪl/ or /sbɪn/. And in North American English, the distinction between /t/ and /d/ disappears at the beginning of an unstressed syllable between vowels; both are realized as the voiced tap [ɾ], as we have seen. (Most speakers, however, make a distinction between the vowels preceding these consonants, so writer and rider do not sound quite the same for these speakers.)
As with the examples of assimilation that we discussed, we've seen aspiration of voiceless stops in English makes some sense, at least from the perspective of the Hearer. But it is still a convention of English, something that we should not necessarily expect in other languages. In Spanish, voiceless stops are never aspirated; in Amharic, they are weakly aspirated in all contexts. In Mandarin Chinese, the relevant distinction is between voiceless stops that are always aspirated and voiceless stops that are never aspirated; that is, there are no real voiced stops. And in Hindi, there is a three-way distinction, between stops that are voiced, stops that are voiceless and always unaspirated, and stops that are voiceless and always aspirated. Finally, even when voiceless stops are aspirated in some contexts but not in others in a language, the pattern may be different from in English. In Tzeltal, voiceless stops are aspirated at the ends of syllables, but not at the beginnings.
Problems
4.3 |
Distribution of phones |
Evidence for learning phonology
Say you're trying to learn about the phonology of an unfamiliar language, but all you have access to is recordings of a set of sentences. You do not know what the sentences mean, nor do you know where the boundaries between the words are. What could you and could you not learn about the phonology of the language given this information?
To gain a better understand of how phonology works, in this section we'll take the perspective of the learner. What does a learner have to achieve with respect to phonology? The learner has to learn to be both a Speaker and a Hearer, to figure out what the categories (phonemes) are and how they are realized in different contexts. What the learner is presented with is allophones of course, not phonemes directly. There are two kinds of evidence that the learner can use to arrive at what the phonemes are.
First, the learner could just pay attention to what phones tend to occur. As I've said a number of times, there are an infinite number of possible phones and, even within a given language, a very wide, if not infinite, set of possibilities. But for a given language, the phones the learner hears will tend to cluster in particular regions within the space of possibilities. For example, if the language is Spanish, there will be many possible vowel phones, but they will tend to cluster around the vowels [i], [u], [e], [o], and [a]. For example, nothing very close to [æ] or [ey] or to [ω] (an unrounded high back vowel) will occur. There will also be many possible consonant phones, but they will tend to cluster around particular points in the space of possibilities. These will include [d̪] (a voiced dental stop), [ð], [t̪], and [ɾ], but not [r] or [t̪h] (an aspirated dental stop) or [t̪'] (an ejective dental stop). Of course these tendencies would be specific to Spanish. [æ] would occur if the language were English; [t̪] would occur if the language were Amharic.
But listening to what phones occur and what phones do not does not provide any direct information on how they are used contrastively, that is, to distinguish words. For example, a child exposed to English will hear a variety of stops in contexts following vowels. Some of these contrast, for example, [t] and [p], but others do not, for example, [t] and [ɾ]. The only way to know for sure that they contrast is to pay attention to meaning as well as to the patterns of phones that occur. For example, if the Learner can tell that [ræt] and [ræp] mean different things, they will know that [t] and [p] contrast.
So there are these two sorts of evidence that the Learner can use: what sounds tend to occur and what different sequences of phones mean.
What there is to be learned
But what sort of knowledge of phonology is there to be learned? We've seen that knowledge of the phonology of a language includes the following.
- Knowledge of what the contrastive categories of the language are, that is, the basic units that are used to make (and distinguish) the words of the language. In spoken languages these include phonemes and supragemental features; in signed languages the contrastive units appear to be syllable types.
- Knowledge of how the contrastive units are realized as particular forms in different contexts. This knowledge needs to be in two forms, one that enables the Speaker to pronounce words and one that enables the Hearer to recognize words.
- Knowledge of how the contrastive units may (and may not) be combined to form words (phonotactics).
In the rest of this section and the next section, we'll be considering how a person would learn the three types of knowledge. To simplify matters, we'll start by looking at a simple imaginary language, the one that a tribe of Lexies has arrived at in an early stage of the evolution of their system of communication. And rather than looking at data on children's production and comprehension, we'll first look at what kinds of information the child might have access to and might be useful in learning about phonology. In fact what I'll be discussing would apply just as well to a linguist who is trying to figure out the phonology of a previously unresearched language.
Of course infants and adult linguists differ in many important ways. For one thing, linguists are conscious of what they are learning about the language; their conclusions will be things they can describe and write down. Infants, on the other hand, are not conscious of any of this and will not even be conscious of the phonological knowledge they have when they grow up. Second, linguists can elicit data; that is, they can ask questions to test their hypotheses. Children obviously could not do this even if they were aware of what they were learning. Still, the task of the linguist and the "task" of the infant bear some interesting similarities.
Say a given child exposed to our imaginary language, or a linguist studying the language, has isolated the following distinguishable forms and associated meanings by a certain point in the learning process. As we saw in the context of the learning of the meanings of words, language learning in any domain would seem to be a challenging task. First, the learner can never know how complete the data are that are available up to a given time. So for phonological learning, the learner cannot know that they have heard all of the phones, that they have enough examples to know what contexts all of the phones occur in, or even that all of the word forms have been heard correctly. Second, the learner could benefit greatly from negative evidence, that is, direct information about what is not a possible form, but this is rare or non-existent. In any case, what the learner has access to is allophones rather than phonemes, so the forms appear enclosed in "[]" rather than "//".
| [po] | 'father' |
| [pi] | 'rock' |
| [pe] | 'sun' |
| [pobo] | 'leg' |
| [pudu] | 'cave' |
| [pana] | 'head' |
| [mi] | 'river, hawk' |
| [maga] | 'rain' |
| [ti] | 'cat' |
| [tu] | 'man' |
| [tede] | 'mosquito' |
| [tunu] | 'milk' |
| [toso] | 'ground' |
| [su] | 'mother' |
| [zu] | 'mother' |
| [sama] | 'eye' |
| [zama] | 'eye' |
| [nu] | 'child' |
| [nasa] | 'tree' |
| [nini] | 'mountain' |
| [ke] | 'woman' |
| [ku] | 'moon' |
| [kene] | 'tiger' |
| [kudu] | 'snake' |
| [kiŋi] | 'path' |
| [ŋo] | 'fire' |
| [ŋobo] | 'hair' |
| [ŋasa] | 'hand' |
Figuring out phonotactics
Let's begin by thinking about the third kind of knowledge, phonotactics, because it will help us figure out the other two. Examining the general structure of the words, we see that they can consist of one or two syllables and that all of the syllables consist of a consonant followed by a vowel. This means that consonants appear in two different contexts, beginning a word and in the middle of a word following a vowel (and preceding another vowel). It also means that vowels appear in two different contexts, at the end of words and in the middle of words preceding a consonant (and following another consonant). So the next question we might ask is whether there are any constraints on which consonants and vowels can appear in which contexts or on which combinations of consonants or vowels occur in two-syllable words. We see that all of the consonants appear in the word-initial context but that only the following ones appear in the third position in two-syllable words: [b], [m], [d], [n], [s], [g], [ŋ]. We also see that all of the vowels can appear in either of the two vowel positions.
In addition, it's hard not to notice a striking regularity to the vowels: in two-syllable words, the first and second vowels are always the same. While languages are usually not this extreme, they often do have constraints on how neighboring phones must agree on some feature. This is true for clusters of final consonants in English, for example. When English syllables end with more than one stop or fricative, these consonants must agree in voicing; that is, either all (or both) must be voiced or all must be voiceless. For example, /kt/, /sk/, /fθs/, /bd/, and /gz/ are possible, but /kd/, /zk/, and /vðs/ are not.
While this language apparently has no stress, if it did we could also look at stressed and unstressed syllables to see if there are phones that can occur in one and not the other type of syllable. In English, for example, unstressed syllables are more constrained than stressed syllables in terms of what can occur.
So we can summarize what we've learned about the phonotactics of the language as follows:
- Syllables always consist of a consonant followed by a vowel (CV).
- Words consist of one or two syllables. In words consisting of two syllables,
- the second syllable can only begin with one of the following consonants: [b], [m], [d], [n], [s], [g], [ŋ]
- the vowels of the two syllables must be the same.
Minimal pairs and overlapping distributions
Say a language learner discovers the following forms in the target language:
- [vam] 'break'; [fam] 'snow'
- [lo] 'picture'; [lu] 'picture'
- [kes] 'lip'; [kes] 'radio'
What does the first pair of words tell us about the status of [v] and [f] in the language? What does the second pair of words tell us about the status of [o] and [u] in the language? What does the third pair of words tell us about the language?
Now we need to figure out what the phonemes of the language are and how they're realized. Obviously it's important to know which phones occur (and which do not). As I noted at the beginning of this section, the phones in a language should tend to cluster around particular prototypical places, places that differ from one language to another. The transcriptions of the words above are meant to represent this. So, based on the words heard, the child has the vowels [a], [i], [e], [u], and [o], and the consonants [p], [b], [m], [t], [d], [s], [n], [k], [g], and [ŋ] to deal with. (Note that a lot of the learning process is being left out here; deciding that there are this many phones, no more or less, is no mean feat, and children may in fact not do anything like that early in phonological learning.)
A particular phone P (really a cluster of phones centered on P) is a phoneme in a language only in the sense that it contrasts with the other phonemes in the language, that is, that the difference between P and those other phonemes can make a difference in meaning. This means that we can only establish what the phonemes are by comparing the different phones with one another. But which pairs should we be comparing and what sorts of comparisons should we be making? There's no point in comparing phones that are very different from one another because changing from one of these to another almost certainly changes the meaning. For example, in English we'd never expect the phones [b] and [s] to belong to the same phoneme. Rather what we're interested in are pairs that are relatively similar. For such pairs it is possible that both phones belong to the same phoneme, or that they belong to different phonemes. "Similar" phones will be phones that differ in only one or two features.
Let's start with the vowels because there are fewer of them. Of the five vowels, pairs that are somewhat similar include [i,e], [u,o], [a,o], and [e,a] ([a] is a low, central vowel). For each pair, we are interested in whether the difference between the two is enough to make a difference in meaning. The best evidence for this would be two words that differ only in that one has one of the phones, and the other has the other. Such a pair of words is called a minimal pair.
We have a minimal pair for [i] and [e], the words [pi] and [pe]. Both of the forms consist of two phones, the first of which is [p]; clearly the only difference is that one has [i], the other [e] in second position. It is important that we not only have two forms that differ in only one way but also that the two forms have different meanings. Otherwise they would not actually be different words. Since [pi] means 'rock' and [pe] means 'sun', and these two meanings are not obviously related to each other, it's clear that [pi] and [pe] are different words. And since the only difference in the forms is the difference between [i] and [e], we can be fairly sure that [i] and [e] are separate phonemes in the language. Let's tentatively call them /i/ and /e/, where the phoneme labels selected are supposed to represent the prototypical allophones. As far as we know so far, these apparent phonemes have only one allophone each, so this is the one we'll select for the phoneme label.
What about [u] and [o], the comparable pair of back vowels of different heights? Looking through the list of words, we find no minimal pairs for [u] and [o]. But this does not necessarily mean that these two phones could not be used contrastively, that is, that they are not separate phonemes. We would have evidence for this if we could show that they are used in the same contexts, that is, that they can appear next to the same phones. If they're used in the same context, then the difference between [o] and [u] can't be due to assimilation or some other process related to context because if this were true, the contexts would have to be different for the two phones. In fact, it would be enough to show that they are both used in one particular context.
The range of contexts that a phone can appear in is called its distribution. We already know that all vowels can appear in one-syllable words and as either vowel in two-syllable words, so a vowel is always preceded by a consonant and sometimes followed by a consonant. What we'd like to know is which consonants can come before and after [o] and which can come before and after [u]. Looking at the words with these vowels, we find that, among other consonants, [p] and [t] can come before both vowels and that [b] can come after both vowels. So the indication is that [o] and [u] occur in the same contexts, or at least that their distributions overlap. Even though there are no pairs of words distinguished only by the difference between [o] and [u], it appears that there could be. For example, based on everything we know about [o] and [u], we could imagine a word pronounced [pu] that would mean something different than the word pronounced [po] 'father'. In other words, it appears that [o] and [u] are separate phonemes. We'll call them /o/ and /u/ tentatively.
We can follow the same procedure for the other vowel pairs. The realization rules for the vowels are simple. Since, as far as we can tell, each vowel phoneme has only one allophone, each vowel is always realized as that allophone.
Complementary distributions
Now let's consider the consonants. One possible set of pairs is consonants that differ only by voicing: [p,b], [t,d], [k,g], [s,z]. In many languages such pairs of voiced and voiceless consonants are allophones of the same phonemes. There are no minimal pairs in the list for any of these pairs of phones, so we need to see whether they can appear in the same contexts, as we did for the pair [o,u]. For [p,b], we discover that [p] appears only at the beginning of words, whereas [b] appears only in the middle of two-syllable words, that is, between vowels. In other words, there is no overlap at all in the distributions of [p] and [b]. In this case we say they are in complementary distribution; there is no overlap at all in their distributions.
Two similar phones that are in complementary distribution cannot be separate phonemes because we can't replace one by another in a form to get a different word. That is, if we're right about the distribution of [p] and [b], we can assume that there could be no form [ba] that would make a minimal pair with the existing form [pa] and no form [popo] that would make a minimal pair with the existing form [pobo].
We can conclude that [p] and [b] belong to the same phoneme. We'll call it /p/, though we have no way at this point of knowing whether [p] or [b] is the prototypical allophone. The realization rules for /p/ are fairly simple. It is pronounced [p] at the beginning and [b] in the middle of words. With [p] as the default allophone, we can see the [b] allophone as resulting from assimilation. In the middle of words, the consonant is surrounded by vowels, that is, voiced sounds, so voicing it (changing it from [p] to [b]) makes it agree with the context on the voicing dimension. For this reason, it makes sense to choose [p] as the default allophone for this phoneme.
Languages tend to be systematic, so we should not be surprised when we find the same sort of distributions for the other stop pairs [t,d] and [k,g]. That is, the voiceless phones in each case appear only at the beginnings of words, while the voiced phones appear only in the middle of two-syllable words. Again we conclude that each pair represents a single phoneme. We'll call these phonemes /t/ and /k/. The realization rules are the same as for /p/, so at the point, we can make a more general realization rule for all three of the stops in the language: Pronounce the stop voiceless at the beginning of a word, and pronounce it voiced in the middle of a two-syllable word (between vowels).
For [s] and [z] we have what at first glance appears to be a minimal pair, [su] and [zu]. But this is not a minimal pair because the two forms have the same meaning, 'mother'. Apparently these are not different words for 'mother', but alternate ways of saying the same word. It is not clear from the list in what situations the different pronunciations are used. One possibility, similar to what we discovered for the pronunciations of English at, is that the pronunciation depends on what precedes the word. Another is that the difference is related to formality, speed, or emphasis. Something like this happens in English with word-final voiceless stops. The /p/ at the end of a word such as lip would normally not be aspirated or released. But if the speaker is speaking unusually formally or slowly or with a great deal of emphasis on the word in question, the /p/ can be released and aspirated.
In any case it's clear that for the pair [su] / [zu] the difference between the [s] and the [z] is not contrastive; changing from one to the other makes no change in meaning. We should also notice the same thing going on with the two other forms beginning with [s] and [z]: [sama] and [zama]. Again the difference in the initial consonants makes no difference in meaning.
So far the evidence that we have indicates that [s] and [z] belong to the same phoneme. If we examine the other forms in the list that contain either [s] or [z], we find only three others, all containing [s] at the beginning of the second syllable: [toso], [nasa], and [ŋasa]. There are no words with [z] in this position. So, as far as we can tell from this list of words, there are no positions in words in which [s] and [z] make different words, and we conclude that [s] and [z] are allophones of the same phoneme. Because [s] seems to occur in more contexts than [z], we can consider it to be the prototypical allophone, and we'll refer to the phoneme as /s/. The realization rules for this phoneme only need to specify that it is optionally pronounced as [z] when it begins a word. Note that the rule is different than the ones for the stops, which get voiced when they are in the middle position in words.
There are three other consonants, the three nasals produced in the same three places of articulation as the other consonants, [m], [n], and [ŋ]. There is a minimal pair for [n] and [ŋ], [nasa, ŋasa], indicating that they are separate phonemes. For the other two pairs, [m,n] and [m,ŋ], there are no minimal pairs, but clear evidence of overlapping distributions: [maga], [nasa], [ŋasa]; [sama], [pana]. So we conclude that there are three nasal phonemes: /n/, /m/, /ŋ/.
Based on the evidence in the list of words, we can propose that the Lexie language has five vowel phonemes and seven consonant phonemes. But it's important to note that our baby has heard just this short list of words; there is more to the language. All of the generalizations that we have made about the phonemes and the phonotactics of the language could prove wrong with more evidence. In particular, whenever we concluded that something could not occur, the child could later discover that such a thing could occur. For example, we concluded that words consisted of one CV syllable or two CV syllables, but it is always possible that a word not yet heard could have a different structure, such as CVC. Similarly, we condluded that [p] and [b] are not contrastive because [p] always occurs at the beginning of words and [b] always in the middle. But the baby could later encounter (or become aware of) a previously unknown word with a form like [be] or [napa]. In fact, even our minimal pairs are suspect. Let's see how.
We've seen that languages use phonemes to distinguish words from one another. But this is only the usual case. We haven't yet considered another possibility for different words. Notice that in this Lexie language, [mi] can mean 'river' or 'hawk'. It's hard to see how these two meanings are related to one another, so we have to conclude that [mi] is really two different words that happen to have the same pronunciation. Such words are called homophones. Many (perhaps all) languages have homophones, probably mainly the result of historical accidents, changes that happened to bring the forms of two words together. Homophones represent an example of ambiguity, a situation in which a form has more than one possible interpretation. We will meet more ambiguity later in the book. Ambiguity presents a potential problem for Hearers because by itself the form cannot be interpreted. Hearers can normally solve this problem by using the context of the ambiguous form, either the other words that it appears with or the situation that it refers to. However, languages normally do not have very many homophones because of the burden this would place on Hearers.
Now consider a minimal pair like [pi] and [pe] again. Because these have different meanings, they are apparently different words, and we used this fact to conclude that [i] and [e] are separate phonemes. But what if [i] and [e] are just allophones of a single phoneme that varies considerably in how it's pronounced, even in a context at the end of words? In that case, [pi] and [pe] would be an example of a pair of homophones, both realizations of a phonemic form that we could write as /pi/. But homophones are rare (for good reason), and it is much more likely that the difference between [i] and [e] is contrastive, as we originally concluded. Still, more evidence would help us decide.
Now let's summarize what we've learned in the form of a set of instructions for discovering the phonology of a language. You can use these a guide when solving phonology problems concerning real languages. But first, remember this caveat: any sample of words is necessarily incomplete, so learners can't be completely sure of their conclusions. It's better to think of the conclusions as hypotheses. The more data there is, the greater the learner's confidence in the hypotheses.
- Learn something about the phonotactics of the language. Begin by looking at the pattern of consonants and vowels that make up the words. This should tell you about syllable structure and maybe about constraints on the form of words. It may also be possible to make more generalizations by examining subcategories within consonants and vowels, for example, voiced consonants, and by looking at suprasegmental features such as stress. In particular, stressed and unstressed syllables may have different structures.
- Within the list of all of the phones you have heard, pick pairs of similar phones. For each, look for evidence that the phones belong to the same phoneme or different phonemes. For each pair, do the following.
- Look for minimal pairs. If you find them, conclude that the phones are separate phonemes.
- If you don't find minimal pairs, look at the contexts that the phones occur in to see if the contexts overlap. Can they be followed by the same or similar phones? Can they be preceded by the same or similar phones? If there is considerable overlap (you have to use your judgement here), conclude that the phones are separate phonemes.
- If the contexts don't overlap, you probably have allophones of
the same phoneme.
To make sure, and to figure out what the realization rules for the
phoneme are, look for the following.
- Try to see if the distributions of the two phones are complementary (the usual situation for allophones). If so, the realization rules are straightforward: the phoneme is pronounced one way in one context (or set of contexts), the other way in the other context (or set of contexts).
- Look for cases where you have forms with the same meaning differing only with respect to the two phones. If you find them, it may be that the choice of allophone in this context depends on factors such as formality. Alternately, if the phone is at the beginning or end of a word, the choice could depend on what phone comes on the other side of the phone.
But what do we see when we look at actual data from children learning the phonology of their first language and adults learning the phonology of a second language? That's the topic of the next section.
Problems
4.4 |
Learning phonology |
Babies learning phonology
Since a newborn infant is (equally) capable of learning any human language, what abilities would an infant have to come equipped with to allow it to learn phonology?
The beginning
As we've seen, languages differ with respect to what is contrastive: all languages treat some distinctions as significant and others as non-significant. In English the difference between [ɪ] and [i] matters — it distinguishes words from one another — but in Spanish it doesn't. In Amharic the difference between [k] and [k'] matters; in English it doesn't. When an infant is born, it is capable of learning any human language. How could it figure out which distinctions are contrastive and which aren't?
Obviously the only information the infant gets to help it is the language that it hears being spoken around it. If it is to figure out which distinctions matter, it has to be able to hear those distinctions. So for example, it has to be able to hear the difference between [i] and [ɪ] or the difference between [k] and [k']. In fact experiments with very young infants indicate that they can perceive all of the distinctions that matter in the world's languages. This is quite impressive since, as we'll see, they tend to lose the ability to hear many of these distinctions later on.
So what happens when an infant starts getting exposed to a particular language? For at least six months after birth, the baby makes the same sorts of sounds regardless of what language this is. (Here's an example of what a baby sounds like at three months.) That is, if we only looked at the baby's production, we would not see any signs that learning is taking place. But it is. Within a few months after birth, babies can distinguish the language around them from other languages that they haven't heard. This means that they have already become sensitive to some of the properties that distinguish languages from each other.
What sorts of properties? Experiments with eight-month-olds show that they are capable of learning the frequencies at which different phones occur together. Nine-month-olds can distinguish sequences of sounds that obey the phonotactics of their language from those that don't and can also distinguish sequences that are frequent in their language from sequences that are phonotactically legal but infrequent (for example, /cʌn/ vs. /tʌš/ in English). Babies apparenlty start learning phonotactics at a very early age. As we saw in the last section, knowing the phonotactics of the target language comes in handy in learning the phonemes of the language because it makes clear what the possible contexts are.
Babbling
Starting at around their sixth month, the sounds that babies make start to take on a different character. This stage, which normally lasts about 12 months, is called babbling. (Here's an example of what a baby learning English sounds like at nine months.) Babies start producing simple syllables, such as [ba], and these may include a very wide variety of consonants and vowels, including many not found in the target language. Later, several things happen. Babies begin to string the syllables together in sequences, such as [bababa] and [batabatabata]. And the sounds they are producing begin to resemble the target language more and more. What happens with deaf children is somewhat more complicated. They begin this phase like hearing children, producing a range of simple syllables. But the sounds they make never get more language-like and never come to resemble the spoken language around them. Deaf children who are exposed to a sign language from birth also go through a sort of sign babbling phase, however, "babbling" with their hands.
What is going on during babbling? It seems to have three related sorts of functions. First, it should be clear from what we've learned about phonology that producing language is very complex and requires a great deal of coordination. In this sense, babbling may be a form of practice; the baby is figuring out how to use its articulatory apparatus in a fluent manner.
Second, the baby has to learn to tie what it hears to what it says. The auditory and the articulatory properties of linguistic sounds are totally different things, but, as we've seen, a particular phoneme needs to be associated with both. How could the baby learn to make this association? It's possible that during babbling the baby tries out various articulatory positions and movements and then listens to the auditory consequences, associating the behavior with the sounds each time this happens.
Third, the baby has to learn to sound more like the target language. This may work through a mechanism known as reinforcement learning. The baby tries out a particular articulatory pattern, listens to the consequences, and if these sound close to the kinds of sounds it is hearing around it, that articulatory pattern gets reinforced for the baby. The result is that the baby is more likely to produce this pattern later on. If, on the other hand, the sound that is produced sounds very different from the linguistic sounds in its environment, that articulatory pattern fails to get reinforced, or is penalized. In that case, the baby will be less likely to produce the pattern later on.
While this is going on, there are also changes in what the baby can perceive. As it begins to learn the phonemes of the language, it begins to lose the ability to hear distinctions that are not contrastive in that language. One well-known example of this phenomenon is the distinction between [r] and [l], a phonemic distinction in English, but not in Japanese, Lingala, Inuktitut, or many other languages. For many speakers of languages like these, the ability to hear the distinction is lost. We'll see more examples when we consider what happens in second language learning below.
Simplification
Children start producing recognizable words around the beginning of their second year. In the beginning what they produce only very roughly approximates the forms they are hearing. Partly this may come from not having worked out what the phonemes of the language are yet; this may take several years. But it also results from the inability to produce some of the distinctions that the child does hear. Production lags behind perception throughout the learning of phonology.
But the forms the child produces in its second, third, and fourth years do not deviate from the adult forms in random ways. Rather they can be seen as simplifications of the adult forms. The kinds of simplification include the following.
- Some phones are inherently more difficult to produce than others, so there tends to be a order in which phonemes are learned. For example, stops and nasals are easier to produce than fricatives. For stops the articulators are brought together completely, whereas for fricatives they must be brought close enough together to yield the characteristic fricative turbulence but not so close as to block the passage of the air completely. The result is that young children may replace fricatives with stops ([mɛti] messy) or replace all fricatives with one fricative that they've mastered ([mɛfi] messy).
- Syllable structure may be simplified. As we saw when we looked at the phonotactics of different languages, the simplest syllables are those consisting of a vowel preceded by at most one consonant. Thus young children sometimes simplify syllables ending in one or more consonants by dropping them ([kæ] cat) or simplify syllables beginning with consonant clusters by dropping all but one of the consonants ([tɑp] stop).
- In words of more than one syllable, children may replace one of the phonemes with another one found in the word ([kiki] kitty), drop a syllable, or combine two syllables ([bænə] banana).
Adults learning phonology
We learned that the Spanish voiced stop phonemes /b, d, g/ are pronounced as approximants when they follow vowels. Yet English speakers learning Spanish tend to pronounce them as stops in all contexts. Why might this be?
When a person learns a language later than in the first few years of life, their success depends on their age, as well as on a range of other factors, though why age matters and which ages, if any, are crucial remain hotly debated issues. Here we'll just consider what happens in adult language learning. I'll be using the term "second language" to refer to any language other than the learner's native language since in most ways the learning of third and later languages follows the same pattern as the learning of a second language.
The learning of second-language phonology seems to be quite independent from the learning of grammar and vocabulary. Most of us are familiar with people whose grammar and vocabulary are indistiguishable from those of a native speaker but who still have a noticeable foreign accent. So what I'll be discussing in this section applies only to the learning of pronunciation. We'll look briefly at the learning of second-language grammar later on.
The phonological learning task of the adult learner is the same as that of the baby: to figure out what distinctions in the target language are constrastive and to learn how to produce and recognize the different phonemes in different contexts. But what we see in adult phonological learning looks quite different from what we see with babies. One clear difference is the amount of variability. Normal children learning their first language end up roughly equivalent in their ability to pronounce and understand the language. Adults, on the other hand, differ dramatically from one another. While the great majority of adults never achieve native-like proficiency in the pronunciation of a second language, no matter how much they are exposed to it, the degree of foreign accent they exhibit varies a lot from one learner to another.
An even more important difference between child and adult language learners stems from the fact that adults already know the phonology of at least one language. This can both help and hinder them in their learning of the new phonological system. In general the influence of a body of knowledge on the learning of new knowledge is called transfer.
The crucial issue is the ways in which the first language phonology agrees with that of the second language. When they agree more or less perfectly, we can expect positive transfer. That is, knowledge of the first language makes the target language easier to learn than it would be for learners with other first languages. For example, as we saw in the section on vowels, Spanish and Japanese vowels are quite similar. In general, it is easier for a Spanish speaker to learn Japanese vowels or for a Japanese speaker to learn Spanish vowels than it is for an English speaker to learn the vowels of either of these languages or for speakers of either of these languages to learn English vowels. Similarly, English and Spanish both have the phoneme /f/, realized in virtually identical ways, whereas Japanese has no such phoneme. In general, then, it is harder for Japanese speakers to learn this aspect of English or Spanish than it is for English or Spanish speakers to learn this aspect of each other's languages.
Much more noticeable in second language phonology are the consequences of differences between the languages. Differences may result in negative transfer, that is, interference from the first language to the target language. As you will see in the section on English accents, accents or languages can differ phonologically in several ways. These differences can often predict some features of foreign accent and areas of phonological difficulty for second language learners.
Phonetic differences
One possible difference is purely phonetic. The first language and the second language both have a similar phoneme P, distinguished from other similar phonemes, but the phoneme differs in the details of how it is produced. Either it is always pronounced differently in the two languages, or it is pronounced differently in some contexts. Learners will tend to pronounce the phoneme as it is pronounced in their first language.
- English /r/, Spanish /r/ ([ɾ])
- Though English /r/ and Spanish /r/ are pronounced quite differently, they have similar auditory properties, so learners will tend to map them onto each other. English speakers will tend to pronounce Spanish /r/ as [r] (in marido and cortar, for example), and Spanish speakers will tend to pronounce English /r/ as [ɾ] (in marry and quarter, for example).
- English /k/, Spanish /k/
- In both languages, this voiceless stop is distinguished from the corresponding voiced stop, /g/, but English /k/ has an aspirated allophone [kh] that is never used in Spanish. Learners should have no problems when /k/ does not begin a stressed syllable. But English speakers learning Spanish will tend to aspirate Spanish /k/ when it begins a stressed syllable, as in que and como, for example, and Spanish speakers learning English will tend not to aspirate English /k/ in any context, including those where it would be aspirated in English, as in come and quick, for example.
Phonemic differences
Another possible difference is phonemic. The second language makes a distinction that is not made in the first language. Learners may fail to hear the distinction and will tend to pronounce the two forms in the same way. Because this sort of difference can interfere with communication, it is more serious than problems of the first type.
- Japanese /r/, English /l/ and /r/
- While English makes a distinction between /r/ and /l/, Japanese has a single phoneme /r/ that is usually pronounced like an alveolar tap ([ɾ]) but sometimes takes the form of an alveolar lateral (similar to English /l/) or a phone that is somewhere in between these two. Which form it takes may be difficult to predict; it depends on the phonetic context, the speaker, and even the situation. Japanese speakers learning English may fail to hear the difference between English /l/ and /r/, so they may not be able to distinguish right from light. And they will tend to pronounce both /l/ and /r/ as either [ɾ] or [l].
- English /k/, Amharic /k/ and /k'/
- As we saw in our discussion of ejectives, Amharic and many other languages make a distinction between plain, non-glottalized voiceless stops and ejective voiceless stops (for example, between /k/ and /k'/), a distinction not made in English. English speakers learning Amharic often have difficulty hearing the difference, so they may not be able to distinguish /kɛbɛro/ 'drum' from /k'ɛbɛro/ 'fox'. And they will tend to pronounce /k/ and /k'/ in the same way, like English /k/.
Phonotactic differences
The languages may also differ in their phonotactics. If the second language has more complicated syllables than the first language, in particular if it allows more complicated clusters of consonants at the beginnings and ends of syllables, it may present special difficulties for the learner. These learners may drop consonants, replace one consonant with another, or add vowels to break up consonant clusters. Another potential problem is a difference in the range of phones that can appear in a particular position, for example, the vowels in unstressed syllables. If the first language is more constrained, the learner may tend to follow those constraints in speaking the second language.
- Beginnings of syllables in English and Japanese
- As we saw in the section on syllables, English allows a variety of consonant clusters at the beginnings of syllables, while some other languages do not. Except for clusters ending in the semivowel /y/, Japanese allows no more than one consonant at the beginning of a syllable, and Japanese speakers may tend to insert vowels between the consonants at the beginnings of English syllables, for example, [gu'ɾeet] for great. Japanese, on the other hand, permits more consonant+/y/ clusters than English does. In particular, Japanese allows syllables to begin with /ry/ ([ɾy]), whereas /ry/ is not a possible syllable beginning in English. English speakers learning Japanese tend to insert a vowel between /r/ and /y/. That is, they may pronounce the words /ryuu/ 'dragon' and /riyuu/ 'reason' the same way, [ri'yu], and may also be unable to hear the difference between these words.
- Unstressed vowels in English and other languages
- English has a strong tendency for unstressed vowels to be pronounced with the vowel /ə/. This is not true for many other languages with stress, for example, Spanish. This means that English speakers will tend to use /ə/ for vowels in some unstressed syllables in Spanish. For example, they may say [,ɛnčə'lɑdə] for [ɛnči'laða] enchilada. In word-final position, English does commonly have /i/ in unstressed syllables, for example, in happy and hurry, and English speakers will sometime replace /ɛ/ or /e/ in final unstressed syllables with /i/. We sometimes see this in the pronunciation of words borrowed from Japanese into English. Even though Japanese does not have stress, English speakers impose stress on words borrowed from Japanese, treating some syllables as stressed and others as unstressed. So the word karaoke is usually pronounced /,kɛri'oki/ in English, whereas the original Japanese word was [kaɾaokɛ].
Suprasegmental differences
As we saw in the section on syllables, languages can use suprasegmental dimensions, especially pitch, in very different ways. It is used as one component of stress in some languages and as a signal for tone or pitch accent in other languages, and it is the major component of intonation in all languages. English and Spanish speakers have little difficulty learning stress in each others' languages, but they may have great difficulty learning pitch accent in a language like Japanese or tone in a language like Mandarin Chinese or Lingala. The situation becomes more complex because of the way intonation interacts with stress, pitch accent, and tone. Thus English uses a sharply falling intonation pattern on words that are being emphasized in statements, for example, when contradicting the hearer, as in the following conversation.
A: That cookie looks good.
B: It's not a cookie; it's a candy.
The first syllable of candy would be pronounced more loudly and with the pitch falling to the next syllable: candy.
In Japanese, the second part of B's line would be
| ame | da | yo |
| candy | is | assrt |
| 'It's (a) candy.' | ||
The word yo at the end of the sentence makes the sentence more assertive.
The word ame means 'candy', but its lexical pitch pattern is one that rises from the first to second syllable: ame. In this emphatic context, the word would be pronounced more loudly, but the pitch pattern would not change because it is part of the word, though the pitch rise might be more exaggerated:
ame da yo. 'It's candy.'
An English speaker learning Japanese will tend to use the characteristic falling English intonation here to signal the emphasis on ame:
But ame with pitch falling from the first to second syllable is a different Japanese word, meaning 'rain', so the English speaker's Japanese would come out as 'it's not a cookie; it's rain'. Here's what the last part of that sentence sounds like in Japanese:
ame da yo. 'It's rain.'
Japanese does not have many minimal pairs such as this differing only in their pitch pattern, but pitch errors of English-speaking learners could still be expected to make their language less comprehensible, especially when combined with other errors at the level of individual phones.
4.5 |
English accents |
In this section we'll look at various English accents and how they differ from one another. The point, aside from learning some important aspects of the English language, is to get a deeper understanding of the concepts introduced in this chapter and the last one by comparing several similar phonological systems. We'll see that the ways in which the accents differ correspond to the kinds of knowledge about linguistic form that we've been discussing: the form that particular words take, the distinctions between phonemes, the detailed realization of individual phonemes, the allophones of phonemes that appear in different contexts, and phonotactics.
Accents revisited
Let's first remind ourselves what an accent is: the set of pronunciation conventions of some speech community. Where we draw the boundaries between accents is pretty arbitrary; if we call General American a single accent, for example, we'll have to deal with the range of variation that exists among speakers within that large community. And any boundaries we draw will be wrong in another sense because the group of people who have one pronunciation convention may not coincide neatly with the group of people who have the other set of conventions that belong to the accent we're considering. For example, the group of speakers who pronounce the words pin and pen the same includes speakers of Southern US accent but also some speakers of General American, which is in may other ways a very different accent from Southern. The point is that conventions of pronunciation tend to cluster together; this is what allows us to talk about "accents" at all.
Another point to keep in mind is that in most countries there is a standard, prestige accent alongside a number of accents associated with particular regions, social classes, or ethnic groups. Each of these non-standard accents can be described in its "broad" form, the form that is most different from the standard in the country where it is spoken, but what many people are speaking much of the time is something in between a particular non-standard accent and the relevant standard. In this section I'll be mostly concerned with broad variants of non-standard accents because they illustrate the range of possible differences best.
When comparing two dialects or accents, one possibility is to see one of them as deviating from the other. A biased view of non-standard dialects often starts this way: the speakers of these dialects are seen as just making mistakes with the standard when what they say is non-standard. But of course this is not what is actually happening. Speakers of non-standard dialects learned the conventions of these dialects by hearing other speakers speak them, just as the speakers of standard dialects learned the conventions of their dialects. They are no more speaking the standard wrong than the speakers of the standard dialect are speaking their dialect wrong.
But there is one situation in which it does make sense to speak of dialect A as diverging from dialect B. Dialects of a single language always started out as a single dialect at some point in the past, and for a given convention, one of the dialects may have changed while the other preserved the original convention. Some people seem to have the sense that standard dialects are conservative, and that non-standard dialects are more likely to change, that is, to introduce "innovations". Sometimes this does happen. In fact some of the conventions that eventually become standard started out as innovations in non-standard dialects. We can see this process going on in England now as features from Londan accent are starting to creep into the speech of people in situations where we'd expect the standard accent of England. But it seems just as likely that the old conventions get lost in a standard before a non-standard. In North America, the distinction between /ɔ/ and /ɑ/ is in the process of disappearing in General American and (standard) Canadian English, while this distinction is maintained (conservatively) in all of the major non-standard dialects. Of course if we are not interested in history when comparing two dialects, which is more conservative doesn't really matter, and we can just treat the dialects as different from one another.
Overview of English accents
Before looking at examples of differences between accents, it might help to have a sense of what the major accents are and where they're spoken. But you can safely skip this subsection if you prefer.
The British Isles
There is no "British" accent. England, Scotland, Ireland, and possibly Wales all have their own unofficial standard accents, and the standards of Scotland and Ireland in particular are as different from that of England as American accents are. The standard, or prestige, accent of England is usually referred to as Received Pronunciation (RP). This is what the royal family, all recent Prime Ministers, and most BBC announcers speak. It is probably what most Americans think of as an "English" accent, though it is spoken as a native accent by no more than about 10% of the English population. It differs most noticeably from General American in the pronunciation of a few vowels and in the way /r/ is treated following vowels. For example, in RP there would be no [r] sounds at all in the phrase the northern fourth of the park.
Within England there are many identifiable regional accents, probably more than in the United States in fact. Among these, London accent (sometimes called "Cockney") stands out because it is familiar to many Americans through film and drama characters such as Eliza Dolittle in "Pygmalion/My Fair Lady" and because it has a number of very characteristic features. Many of the vowels in this accent differ considerably from RP (and General American). Other very striking features are the loss of initial /h/ ("'e 'as an 'ard 'eart" = "he has a hard heart") and the frequent glottal stops in place of other stops in other accents ("iʔ'll taʔe a loʔ o' time to seʔle" = "it'll take a lot of time to settle"). Perhaps the other major accent boundary in England separates the accents of the north from those of the south. Americans may be familiar with northern England English through the speech of the Beatles or the characters in films such "The Full Monty". These accents can be identified fairly easily because they make no distinction between the vowels /ʌ/ and /ʊ/; both are pronounced like /ʊ/.
Scottish and Irish English share one feature with northern England English; the tense vowels /i/, /u/, /e/ and /o/ are not pronounced as diphthongs, as they are in RP (and General American). In addition, these accents are like General American, and unlike most accents of England, in how they treat /r/ after vowels.
The Western Hemisphere
The unofficial standard accent of the United States is usually called General American (GA). This is the accent of much of the Midwest and the West and the most frequent accent for US newscasters, though, interestingly, only five of the last eleven US Presidents have spoken it. As the prestige accent, it has been encroaching on some regional accents, for example, in the northeast, but at the same time, changes within GA are creating what amount to new accents. One striking example of this is Northern Cities accent, spoken in cities such as Chicago, Detroit, Cleveland, and Rochester, and distinct from GA in the pronunciation of lax vowels.
Most English speakers, at least in the US, are familiar with Southern US accent, spoken by people mainly in the southeastern part of the country. Like London accent, this accent has strikingly different vowels from other English accents. African-American Vernacular English (AAVE) is a dialect associated with an ethnic group rather than a region, though of course you don't have to be African-American to have learned it. The accent associated with this dialect is similar in many ways to Southern US accent, while the grammar has its own characteristic properties.
People from the northeastern US are often easy to identify by their accents; the accent of New York City stands out within this region, again mostly for its vowels. Some other US cities, especially Pittsburgh, are known for particular pronunciation conventions. In Pittsburgh, for example, [a] may be used where GA has /aw/, so downtown may be [,dan'tan].
Standard Canadian English (except in the province of Newfoundland) is very similar to General American, and it doesn't vary much from place to place. Two features that can help identify Canadians are their pronunciation of /ay/ and /aw/, which we'll learn about later, and a tendency to use rising pitch at the end of some statements as well as questions.
English is the native language of much of the Caribbean, with some features common to the region and others specific to particular islands. Americans may be familiar with Caribbean English through the speech of Jamaican performers of reggae music. As with other accents, there are characteristic vowels in these accents, and in addition, a tendency in the Caribbean, as there is in some accents of the US and England, to make no distinction between /t/ and /θ/ and between /d/ and /ð/. Jamaican English in particular also has quite striking intonation patterns.
The Southern Hemisphere
English is the native language of most Australians and New Zealanders and a sizable minority of South Africans. While the standard English accents of these countries tend to approach RP, the broad accents of most English speakers in all three countries have tense (long) vowels similar to those in London accent. The lax (short) front vowels of Australian and New Zealand English differ from those in other accents. Americans are likely to be familiar with these features from the speech of actors such as the Australian Paul Hogan.
Non-native accents
English is spoken as a second language by millions of people, especially in regions that were once colonized by Britain in South Asia and Africa. In some of these regions there are particular English pronunciation conventions that derive from the phonology of the local languages. So in the English of South Asians (Indians, Pakistanis, Bangladeshis, Sri Lankans, Nepalese, Bhutanese, and Maldivians), the alveolar consonants /t/, /d/, /n/, and /l/ tend to be replaced by retroflex consonants, an important place of articulation for consonants in the languages of this region. Some of these conventions may be viewed as belonging to a kind of non-native regional or national English standard. These non-native standards are one of the ways in which English is becoming even more of an international language.
Phonetic differences
You learn that the phoneme /e/ is pronounced [yɛ] in Jamaican English. As a speaker of General American, how easy would it be for you to master this aspect of a Jamaican accent?
Probably the most common sort of difference between accents is purely phonetic. A phoneme in one accent corresponds perfectly to a phoneme in another accent, so we can consider it to be the same phoneme, but it differs in its precise realization, that is, how it is articulated and perceived.
Take the vowel /o/. In GA, this is pronounced as a diphthong beginning as a rounded mid back vowel and ending as a rounded high back vowel (or semivowel): [oʊ]. In RP, on the other hand, this same phoneme has a slightly different realization. It begins as an unrounded mid central vowel and ends as a rounded high back vowel: [əʊ]. In other accents, such as Irish, Scottish, and northern English, /o/ is not a diphthong at all; it is realized as [o]. But since the set of words in GA with [oʊ] is the same as the set of words in RP with [əʊ] (with perhaps a few exceptions) and the other accents with [o], we can see these as the same phoneme. If you're a speaker of GA, and you want to sound English, one thing you could do would be to simply pronounce all instances of /o/ in your speech as [əʊ], just as a speaker of RP could pronounce all instances of /o/ as /oʊ/ as a part of affecting an American accent.
Another similar example concerns the vowel /ɑ/, as in the words hot, sock, and rob. In RP, this vowel is pronounced in roughly the same position as it is in GA (that is, with the same height and backness), but in RP it is somewhat rounded (leading some Americans to think that the RP vowel in these words is /ɔ/). Sometimes a different symbol is used for the vowel in fact. But this difference between the accents is a bit more complicated than this because, as we'll see below, it applies to only some instances of /ɑ/ in GA.
For English vowels, the pattern of phonetic differences between accents is often more extensive than just the correspondences between individual phonemes. The realization of a number of vowel phonemes in one accent may correspond to different realizations for all of those phonemes in another accent. This may be true for the lax ("short") vowels or the tense ("long") vowels or both.
Let's compare the tense vowels, including the diphthongs, of GA and London accent. These accents have the same set of tense vowel phonemes, which we have been writing using the symbols /i, e, u, o, ay, aw, ɔy/, but each is realized differently in the two accents, in some cases, very differently. The first figure below summarizes what you already know about the tense vowels of GA. Recall that each of these vowels is actually pronounced like a diphthong, though this is not reflected in the symbols used for /i, e, o, u/ and it may be difficult to hear or feel for /i/ and /u/. Each line represents one of the phonemes, and it is labeled with a word containing the phoneme (written in the same color as the line). Circles at one end or the other of an arrow represent rounding, and the arrows next to the words show the direction of the diphthong. The second figure shows the corresponding vowels in London accent. Click on the words to hear my imitation of a Londoner saying them. The colors in the two figures represent phonemes that correspond, though in some cases they differ considerably in their phonetic realization, as you can see.
The main point to note here is that there is a clear correspondence between the GA and London vowel phonemes, even though the correspondences might not be reflected in the symbols that we use to represent the phonemes. For example, we have been using /e/ to represent the vowel in bait, but [e] is very far from the vowel in this word in London; for London accent, a better symbol would be [aɪ], which of course is the realization of a completely different phoneme in GA, the one in the word bite. So when we are talking about two phones in different accents, there are two ways we can compare them, phonetically and phonemically/lexically. Phonetically, the vowel [aɪ] in London, as in the word bait, is quite similar to the vowel [aɪ] in GA, as in the word bite. But phonemically or lexically, the vowel [aɪ] in London functions the same way as the vowel [eɪ], that is, /e/, in GA.
Phonemic differences
You're a young speaker of a Caribbean accent in which there is no /θ/ or /ð/ phoneme (thing is /tɪŋ/; this is /dɪs/). When you start school, you're expected to learn a prestige accent in which distinctions are made between /t/ and /θ/ and between /d/ and /ð/. In what ways might this be difficult for you?
Another possibilitity is that two accents may differ in the number of phonemes. That is, a distinction that is made in one accent and used contrastively is not made in the other accent. This means that some words that contrast in one accent may sound the same in the other accent.
I have already mentioned two examples of this phenomenon. Many, perhaps most, speakers of GA and Canadian English do not make a distinction between the phonemes /ɔ/ and /ɑ/; they have a single phoneme instead. The actual phonetic character of the sound varies somewhat; it is more like [ɑ] for Americans but more like [ɔ] for many Canadians. The point is that the speakers do not distinguish words from one another using a distinction between [ɑ] and [ɔ]. Pairs of words like the following are distinct in other English accents, but they sound the same for these speakers.
- awed, odd
- dawn, Don
- cawed, cod
- caught, cot
In these accents, there is a distinction between /ɑ/ and /ɔ/ before /r/, for example, in pairs such as car and core, part and port, lard and lord. But in this same context, there is no distinction between /ɔ/ and /o/, so we could consider a word such as core to be /kor/ rather than /kɔr/.
Because these pairs of words sound the same in this accent, there is a potential problem for the hearer that does not exist in an accent where the distinction is made. We know that this feature of this accent is relatively new; that is, the earlier distinction made in this and other accents has been lost (and is apparently being lost by more and more speakers). Given the problem that hearers have distinguishing words like the pairs above, how can such a change take place? In fact it turns out that there are very few such pairs. The additional burden on the hearer is apparently small enough that the loss of the distinction is tolerated by speakers and hearers of the accent.
Another example was also mentioned earlier, the lack of a distinction between the phonemes /ʌ/ and /ʊ/ in accents of northern England. For these speakers there is a single phoneme, normally pronounced [ʊ]. So the following words, which sound different in most other accents, are pronounced in the same way by these speakers.
- cud, could
- buck, book
- luck, look
- putt, put
- stud, stood
In this case, unlike that of /ɑ, ɔ/ in North America, it is the accent that fails to make the distinction that is more conservative; Middle English did not make a distinction between /ʌ/ and /ʊ/. In any case, as before, the lack of a distinction does not leave hearers for this accent handicapped because there are not many pairs of words distinguished only by this difference.
As a final example of phonemic differences in English vowels, consider how the vowel /ɑ/ in GA corresponds to vowels in RP. In GA this vowel appears in words where it is spelled "o" — hot, shock, stop — and words where it is spelled "a" — father, part, carve. In RP, on the other hand, these sets of words have different vowels, a short, rounded, low, back vowel in the first set (which I'll write with /ɑ/ even though it differs a little from GA /ɑ/) and a long, unrounded, low, back vowel in the second set (which I'll write /ɑ:/). That is, in RP, the words father and bother do not rhyme. Most of the words with /ɑ:/ in RP have an /r/ in GA that does not appear in RP, as we'll see below. This means that, even though RP has two vowel phonemes where GA has one, there are few if any words that are distinguished in RP but not in GA. For example, a pair such as pot and part is distinguished by the consonant (/r/) in GA but by the vowel in RP (GA: /pɑt/, /pɑrt/; RP: /pɑt/, /pɑ:t/).
But RP /ɑ:/ also corresponds to many words that have /æ/ in GA. Some words are pronounced with /æ/ in both accents, for example, gas, bad, can, and lamp. Other words with /æ/ in GA are pronounced with /ɑ:/ in RP, for example, glass, rather, can't, and laugh. Note that there is in general no way to predict from the context which words will have /æ/ and which will have /ɑ:/ in RP. Thus an American trying to imitate an RP accent will have to remember which words have which phoneme. This is difficult and leads to frequent over-generalization mistakes such as the pronunciation of gas as /gɑs/ or stand as /stɑnd/ in American attempts at imitating RP.
Differences in the number of English consonant phonemes are not as common, but there are some. In a number of accents, especially in the Caribbean, in London, in AAVE, and in some US cities, the dental fricatives /θ, ð/ do not exist as separate phonemes. Where other accents have these phonemes, these accents have either /t/ and /d/ or /f/ and /v/. So in accents where /θ/ is not distinguished from /t/ and /ð/ is not distinguished from /d/, each of the following pairs of words would sound the same.
- tin, thin
- tie, thigh
- boat, both
- true, through
- tread, thread
- den, then
- ride, writhe
In these accents an older distinction has been lost, but as with /ɑ/ and /ɔ/ in North America, the loss apparently does not seriously interfere with communication because there are not too many pairs of words that end up as homophones with the loss of the distinction.
Going back and forth between two accents is more complicated when the number of phonemes differs than when there are only phonetic differences. Say a speaker of GA or Canadian English who does not make the distinction between /ɑ/ and /ɔ/ wants to learn or to imitate the speech of someone from London or New York or Houston, all places where the distinction between these two phonemes is made. The problem is that words with these phones in this person's mental lexicon are all represented in terms of one vowel category, whereas the same words are represented in terms of two different categories in the mental lexicons of speakers of other accents. For each word, say, caught or hawk or hot or lock, the speaker will have to figure out which vowel in the other accent is appropriate. But unless the speaker has learned this for each word, this will be impossible. In this situation, speakers often make mistakes, over-extending either one or the other phone. For example, a North American speaker might overuse /ɔ/ in trying to speak with an RP accent, using this vowel for words like hot and lock. In the same way, a speaker from northern England trying to speak with an RP accent, might over-extend the vowel /ʌ/, using it for words normally containing /ʊ/ such as sugar and cushion.
Note that a speaker going in the other direction would not have the same problem. A speaker of RP would just have to remember to pronounce both /ɑ/ and /ɔ/ in the same way when imitating GA and to pronounce /ʌ/ and /ʊ/ in the same way when imitating an accent of northern England.
Allophonic differences
A further possibility is for two accents to differ in the way a phoneme is realized in different phonetic contexts. The allophones of the phoneme may differ, or the contexts in which they apply may differ. Let's consider /t/ again, a phoneme with a wide range of allophones in many English accents. In the context where it is surrounded by vowels and does not begin a stressed syllable, this phoneme is realized as a tap, [ɾ], in GA, Canadian, Australian, and New Zealand accents, for example, in words like butter, settle, and city and phrases like put it on and at a glance. Speakers of most accents of England never use this allophone, however. Instead, some of them, especially London speakers and others whose speech is under the influence of London accent, use a glottal stop, [ʔ], in this same context. The glottal stop is a possible allophone of /t/ in GA, but only in the context where it follows a vowel and precedes a consonant, for example, in outright chaos and let me go. In these contexts, even more speakers in England also have glottal stops.
Another place where English accents often differ with respect to their allophones is the pronunciation of /l/. All English accents have an /l/ phoneme, but it may be realized differently. In many accents, including GA and RP, there are two allophones, a "clear" one, for which the tongue body is pushed up and forward, and a "dark" one, for which the tongue body is pulled backwards. Most GA speakers use the clear allophone only when it comes at the beginning of a syllable (possibly at the end of a consonant cluster), for example, in live, play, and relate. (For comparison, here's how these words would sound with very dark /l/s: live, play, relate.) In other contexts, for example, in full, old, and silly, GA speakers use the dark allophone. (For comparison, here's how these words would sound with very clear /l/s: full, old, silly.) (Note that this description of the contexts requires that we treat the syllable boundary in silly as occurring between the /l/ and the /i/.) In RP, the clear allophone is generally even clearer than in GA (a phonetic difference), and it is used in word such as silly as well, though not in full and old. That is, in RP, we can say that the clear allophone of /l/ occurs generally before vowels. In other accents, one or the other variant of /l/ may be used always. In Irish English and Caribbean English, the clear /l/ tends to appear in all contexts, while in Scottish English, the dark /l/ tends to appear everywhere. So in these accents we can say that /l/ has only a single allophone.
Accents may also differ in their vowel allophones. The Southern US accent has unusually complex lax ("short") vowel phonemes. In fact "short" is not at all appropriate for this accent since these vowels are often longer than the "long" vowels. In particular, each of the front lax vowel phonemes, /ɪ/, /ɛ/, and /æ/, has a wide range of possible realizations, depending on the place of articulation of the following consonant, the backness of the next vowel, and whether the vowel is in a word consisting of one syllable. Each of these vowels has at least one diphthong allophone. Listen to the vowels indicated in bold in the following sentence:
Each is realized as a diphthong. When these same vowel phonemes appear before /k/, however, they have (non-diphthongal) allophones close to the GA vowels.
- Mick wrecked the jack.
Since all of these allophonic differences concern realization and not how words are represented in the lexicon, they are more like the phonetic than the phonemic differences discussed above. If a GA speaker wanted to imitate a London speaker's use of the glottal stop allophone of /t/, they would only have to worry about what context each /t/ occurred in, using a glottal stop whenever the /t/ occurred after a vowel and not at the beginning of a stressed syllable. Words in the GA speaker's lexicon with /t/ would also have /t/ in the lexicon of a Londoner, so there would be no need to remember new properties of individual words.
Phonotactic differences
Some accents (such as AAVE and Caribbean) do not permit consonant clusters such as /st/ and /nd/ at the ends of words, while other accents (such as GA and RP) do. With respect to just this property, would you expect it to be easier for a speaker of AAVE to learn GA or for a speaker of GA to learn AAVE?
Accents can also differ from one another in their phonotactics, that is, in the way in which consonants and vowels combine to make syllables. The most noticeable place in English where there is this sort of variation is in the distribution of the phoneme /r/. In most accents, /r/ can occur freely at the beginnings of words, both alone (rat) and in clusters (brat). In GA, however, there are restrictions on which vowels can occur before /r/ within a word. For many speakers, the vowels /i, e, u, o, ʌ/ cannot occur before /r/. In RP (and many other accents, including AAVE and some southern and northeastern US accents), the restrictions are even more severe: /r/ can only occur before a vowel. That is, in words such as harm, port, hurt, and weird, there is no [r] sound at all in these accents. And in words such as car, pour, her, hair, here, fire, and power, there is no [r] sound unless the words immediately precede a vowel in the following word. So the following sentence has no [r] sounds in RP, imitated here by me.
In fact the situation in RP is more complicated than this. First, where there used to be /r/ after a vowel, and where there still is today in most accents, RP sometimes has a [ə], resulting in the diphthongs /ɪə/, /ɛə/ and /ʊə/. These diphthongs are considered to be separate vowel phonemes in some descriptions of RP. There are also pairs of homophones in RP that differ in GA and other accents, for example, farther/father and source/sauce. One further complication is that [r] gets inserted in some contexts in RP. But I'll save this for a later section.
Another example of restrictions on the distribution of a phoneme concerns the vowels /ɪ/ and /ɛ/ in Southern US English (and also the English of some neighboring regions), which we've run into before. In these accents, the distinction between /ɪ/ and /ɛ/ is neutralized before [n]; only /ɪ/ occurs in this context. So in these accents, the following pairs of words are pronounced the same.
- pin, pen
- tin, ten
- since, sense
- sinned, send
- mint, meant
As with other cases of the loss of a contrast, there is the possibility of a burden on the Hearer because of the words that are no long distinguished. This loss may explain why speakers of these accents seem to replace pen and pin with longer expressions such as fountain pen, ballpoint pen, and straight pin. Note that pen and pin are both nouns referring to physical objects, so there might be some confusion on the part of a hearer for these two words.
Finally, English accents may differ in what sorts of consonant clusters are possible. AAVE and Caribbean accents, for example, have more restrictions on what can occur at the ends of words than GA or RP do. For example, word-final consonant clusters ending in /p/, /t/, /k/, or /d/ in other accents are simpler or different in these accents: wasp /wɑs/, list /lɪs/, left /lɛf/, act /æk/, desk /dɛs/, ask /æks/, find /fayn/, cold /kol/, loved /lʌv/.
Lexical differences
In the United States some words have pronunciations that are stigmatized; some of the pronunciations are associated with particular regional accents. Examples are get pronounced /gɪt/ and once pronounced /wʌnst/. If you spoke an accent that included these pronunciations, how easy do you think it would be to learn to pronounce such words in the standard (prestigious) way?
A final way in which accents can differ is lexically, that is, in the conventional pronunciation for particular words. For example, a small number of words are pronounced differently by GA and and RP speakers (and most other speakers on the two sides of the Atlantic). Examples include schedule (GA: /'skɛǰəl/, RP: /'šɛǰəl/), tomato (GA: /tə'meto/, RP: /tə'mɑ:to/), laboratory (GA: /'læbrə,tɔri/, RP: /lə'bɔrətri/), lieutenant (GA: /lu'tɛnənt/, RP: /lɛf'tɛnənt/), figure (GA: /'fɪgyər/, RP: /'fɪgə/, beta (GA: /'betə/, RP: /'bitə/). Note that none of these differences is related to any more general difference between the accents; that is, it could not be predicted from what we know about the phonetic, phonemic, allophonic, or phonotactic differences between GA and RP.
There are also lexical differences between GA and other US accents, especially broad Southern and AAVE. Some examples are police (/pə'lis/ vs. /'polis/), wash (/wɑš/ or /wɔš/ vs. /wɔrš/), yellow (/'yɛlo/ vs. /'yælər/), and catch (/kæč/ vs. /kɛč/).
Other lexical differences may apply to larger sets of words. One way this can happen is with the pronunciation of parts of words that recur in many words. The word ending spelled -ile occurs in many English words such as fertile, docile, mobile, and sterile. This ending is normally pronounced /əl/ in GA but /ayl/ in RP. A more familiar example is the pronunciation of the word ending spelled -ing in words of more than one syllable, that is, words like playing, eating, and something, but not thing and sing. Some speakers, located in various places in the English-speaking world, always pronounce this ending /ən/. Many other speakers have two pronunciations for the ending, one reserved for more formal situations, the other for more informal situations. For RP speakers and many GA speakers (including me), the formal pronunciation is /ɪŋ/ and the informal pronunciation /ən/. For other GA speakers (a group that appears to be growing), the more formal pronunciation is /in/.
Even though these differences in pronunciations of word parts such a -ile and -ing apply to large numbers of words, they still need to be seen as lexical differences since there is nothing in what we know about the phonetic, phonemic, allophonic, or phonotactic differences between the accents that would allow us to predict the different pronunciations from the contexts of the phones.
Learning to change your pronunciation of particular words, for example, if you want to make your pronunciation more standard or want to imitate a different accent, is not too difficult, as long as there are no differences of other types (phonetic, phonemic, allophonic, phonotactic) to worry about. On a word-by-word basis, you just have to remember the new pronunciation in terms of the phonemes that are part of your native accent.
Suprasegmental differences
In the section on syllables, we saw that languages vary in terms of how they use the dimensions of pitch, loudness, and duration. One very noticeable difference between English accents is in the details of how these dimensions interact with the structure and the meanings of sentences, that is, in their intonation. Because of the inherent difficulty of describing intonation, however, these accent differences are apparently not as well studied as differences at the level of consonants and vowels.
One difference between GA and RP is in the typical pitch pattern used for yes/no questions, that is, questions that can be answered with yes or no, rather than with phrases like Felix or on Tuesday. In GA, the usual pattern for these questions involves a pitch rise on the stressed syllable of the last stressed word in the sentence followed by a continuing high pitch on succeeding syllables. In RP, the syllables leading up to the stressed syllable of the last stressed word in the sentence are relatively high, and the pitch falls on that stressed syllable and then rises to a high pitch again, remaining high for the rest of the sentence as in GA. Consider the following question in the two accents.
- Has she written to you?
- Has she written to you?
This difference in intonation is similar to phonetic, rather than phonemic, differences at the level of consonants and vowels because it does not involve more distinctions made in one or the other accent. It is just the realization of the yes/no pattern that differs for the two accents.
We've seen that accents within a language can differ in all of the characteristic ways that languages differ from one another. What makes accent differences special is the fact that the different dialects are related to one another; they ultimately derive from the same dialect in the past. This means that either phonemes in one accent correspond directly to phonemes in the other accent, or, if phonemes have split or merged in one of the accents, one phoneme in one accent corresponds to multiple phonemes in the other. These correspondences are easy to observe because of the correspondences between words in the different accents. The word cat is [khæt], [khat], [khɛət], and [khɛt] in different accents (GA/RP, Scottish/Northern English, Northern Cities, Australian/New Zealand), and from the lexical correspondences we can discover the vowel correspondences. One interesting kind of information that we can infer from these sorts of correspondences is the history of the dialects, how the parent dialect turned into the different daughter dialects. Of course the same is true for related languages. That is, we could learn something about the history of Spanish phonology by looking at correspondences between words in modern Spanish and related languages such as French and Portuguese. We'll see more about how this works in the section on phonological change.
4.6 |
Phonological change |
Phonetic change
What do you think would be the consequences if, for some reason, the phoneme /i/ in English started to become more and more similar to the phoneme /ɪ/? Think in terms of what this would mean for the Hearer. How might the English phonological system deal with such a change?
One way the pronunciation of a language can change over time involves changes in how particular phonemes are pronounced but not in the number of phonemes. As with other language change, it is usually not clear how the change begins, but the prototypical phone for some phoneme starts to move. In the simplest case, this is all that happens. For example, about 150 years ago the vowel /o/ in some dialects of English, already a diphthong, began to shift so that its beginning was more central and less rounded, resulting in the characteristic [əʊ] of today's Received Pronunciation.
More often a change in one phoneme affects others.
This is because the change may either make that phoneme more similar to another
or open up a region in the phonetic space where there is no phone.
In the former case, the changing phoneme may "push" another phoneme away as it
comes close to it.
In the latter case, the changing phoneme may "pull" another phoneme into the
region where it used to be.
Both kinds of changes favor the Hearer because they keep the phonemes as far apart as
possible.
These processes are best known from the history of vowel systems.
The vowels of English have undergone several such changes and in some English
dialects are undergoing them now.![]()
Probably the most famous example of such a set of changes is the Great Vowel Shift of Middle English. I won't go into it in detail, but what happened was that the pronunciation of all of the tense (long) vowels of English changed, in some cases quite dramatically. For example, the vowel in words such as fine had been pronounced [i]; eventually it became the [ay] of Modern English.
Instead we'll look in detail at some changes going on in the vowels of one English dialect today. A quite striking set of changes is happening in some cities of the Northeast and the Midwest in the US (for example, Rochester, Cleveland, Detroit, Chicago, and Milwaukee). This is called the Northern Cities Vowel Shift; in its most extreme cases, it applies to the set of all of the English lax (short) vowels except for /ʊ/. You can read more about the Northern Cities Vowel Shift in this paper. The figure below diagrams the changes.
The diagram shows what is happening in vowel space (front vowels on the left). Each arrow indicates the direction of change for one phoneme. The phoneme label and example word appear in the position where the vowel started, that is, its position in General American. The end of each arrow shows where the vowel ends up in the cases where the shift has progressed the furthest. For example, the word cot following the shift is pronounced something like the word cat in General American. The order of the changes is indicated by the numbers. Different speakers, and to some extent different cities, can be seen as being currently at different points within the set of changes. For examples, for some speakers, only changes 1 and 2 might have taken place, whereas for others all of the changes might have taken place. There is also considerable variation, so we should not expect everybody in the Northern Cities to follow exactly this pattern.
The first change to happen was a movement of the /æ/ vowel higher. (Incidentally a similar change has happened in other accents of the US Northeast, but it is normally confined to only some contexts, for example, in glad but not back.) As the vowel moved higher, it also tended to become a front-to-central diphthong. The diagram shows the most extreme change; more moderate changes occurred within the speech of many speakers. Note that once /æ/ has shifted like this, it is the same phoneme as it was in the sense that it is still distinguished from all of the other vowel phonemes in this English dialect and is still used for the same set of words as before (back, glass, fancy, etc.). But phonetically it is no longer [æ], so we could choose to represent the phoneme with a different symbol. Keeping the symbol the same, however, reminds us how this phoneme corresponds to the /æ/ of other dialects.
Apparently the next change to take place was the movement of /ɑ/ forward. This is an example of a "pulling" change; the movement of /æ/ left a gap in the vowel space that /ɑ/ moved to fill so that the vowels remained roughly equally spaced. Again for most speakers the change was not as dramatic as shown in the figure; for many the vowel is closer to [a] (a low central vowel) than to [æ].
The next change to take place seems to have been the movement of /ɔ/ downward. As you'll see in the section on English accents, this change has happened for many North American speakers, but in other accents, the /ɔ/ and /ɑ/ vowels are no longer distinguished. In the Northern Cities, the two vowels remain distinct, and the movement of /ɔ/ can be seen as another example of a "pulling" change since the movement of /ɑ/ opened up a place for /ɔ/.
Next the vowel /ɛ/ became more central. Again this is an example of a change that seems to be occurring more generally in North America, though apparently only in some contexts, for example, in the word level. In the Northern Cities accent, it was probably a response to the rising /æ/ As this vowel became higher, it came to resemble /ɛ/, and there was the potential for confusion since many words in English are distinguished by the distinction between /æ/ and /ɛ/ (for example, bat and bet). As a result, /ɛ/ shifted so that it would be more distinct. This is an example of a "pushing" change; the /æ/ pushed the /ɛ/ into another region of the vowel space.
Next /ʌ/ became more back. This can be seen as both a pulling and a pushing change, pushing because /ɛ/ became more confusable with /ʌ/ as it moved back, and pulling because /ɔ/ opened up a gap in the vowel space when it moved down.
Finally /ɪ/ also moved back. This is an example of a pushing relationship. As /æ/ rose, for some speakers it seems to have reached the point where it became potentially confusable with /ɪ/, and /ɪ/ moved back to make room for it. This is also a change that seems to happening more generally in North America, though again apparently only in some contexts, for example, in the word liver.
Change in some contexts
Another possibility is that a phoneme will come to be pronounced differently in some contexts but not others. In other words, the realization rules for that phoneme change. Often the changes are examples of assimilation. Here are some examples from the history of English.
- Old English /k/ before /i/
- In Early Old English /k/ came to be palatalized when it occurred before /i/; that is, the point of articulation moved forward from the velar to the palatal region. This is an example of anticipatory assimilation; the /k/ changes to be more like the /i/, for which the high tongue position is near the palatal place of articulation. Eventually /k/ in this context became similar to [č], that is, an alveopalatal affricate.
- Final unstressed vowels
- At several times in the history of English, final unstressed vowels have been dropped. In Old English, which had no /ə/ phoneme, there were many words such as /'sʊnʊ/ 'son' with final unstressed vowels that are quite unlike unstressed vowels in Modern English. At some point, unstressed vowels in words such as these became reduced to /ə/, and later this vowel when it was final ceased to be pronounced altogether. This is the reason English has so many "silent e's"; the orthography has been conservative and fails to represent all of the phonological changes.
Phoneme loss
A further possibility is that two phonemes will merge as a result of change in one or the other or both. Obviously this can only happen when the difference between the two phonemes is not so significant in the language, that is, when the phonemes do not distinguish many words. In the section on English accents, we'll see several examples of this. In many North American dialects, for example, the vowels /ɔ/ and /ɑ/ have merged in recent years. This does not create a serious problem for the Hearer because there are not many minimal pairs such as awed/odd and caught/cot that are distinguished only by these phonemes.
Phoneme creation
We saw in the last section how phonemes could be lost. Given what you know about allophones, how might the opposite process take place? That is, how might allophones of the same phoneme (for example, [t] and [th] in English) turn into separate phonemes?
If phonemes can be lost, it stands to reason that they can also be created. Otherwise languages would tend to have fewer and fewer phonemes, making them more and more difficult for the Hearer. There are at least two ways that new phonemes can emerge in the history of a language. In both of the ways we'll look at, the phoneme starts as the allophone of an existing phoneme.
One way in which an allophone can turn into a phoneme results from the borrowing of words from another languuage in which that phone is a separate phoneme already. We have seen that [v] was an allophone of the phoneme /f/ in Old English, not a separate phoneme. But following the Norman conquest of England in the 11th century, English borrowed many (Norman) French words. Some of these words contained [v] (a separate phoneme in French), and some of these were in positions where the [v] allophone of /f/ did not occur, for example, at the beginning of words (very). Once [v] was appearing in positions where [f] could appear, that is, once the distributions of [v] and [f] overlapped, it was a separate phoneme in English. After this the distinction between /f/ and /v/ could be used to distinguish words from each other, for example, fine and vine.
Phonemes may also emerge out of allophones when other changes combine to make the contexts for different allophones overlap. This is what happened in Old English in the case of /č/, originally an allophone of /k/ before /i/, as we saw above. When other changes caused [k] also to appear sometimes before [i], the contexts for [k] and [č] overlapped, and they were now separate phonemes, distinguishing some words from one another. These changes are summarized in the table below, which also illustrates the emergence of another phoneme in Old English, /ü/, a high front rounded vowel. (You are familiar with this phone if you happen to know French, German, Dutch, Swedish, Hungarian, Finnish, or Mandarin Chinese.) The symbol [-] represents vowel endings that are irrelevant for the discussion, and "→" represents a sound change. The table shows what happened over a period of several hundred years. The change is illustrated with two examples, the Old English words for 'kin' and 'chin'.
| 'kin' | 'chin' | Change | |
| 1 | [kunni] | [kinn-] | |
| 2 | [kunni] | [činn-] | Palatalization: [k] → [č] before [i] |
| 3 | [künni] | [činn-] | Vowel fronting: [u] → [ü] when the next vowel was [i] |
| 4 | [künn] | [činn] | Deletion: some final vowels dropped |
| 5 | [kinn] | [činn] | Derounding: [ü] → [i] |
Originally the words for 'kin' and 'chin' began with the same consonant phoneme, realized as [k] in both words. Then, in period 2, in a change already discussed above, /k/ in the context of a following /i/ came to be realized as [č]. At this point [č] existed in the language, but only as an allophone of the phoneme /k/. That is, the allophones [č] and [k] were still in complementary distribution. In period 3, the vowel /u/ came to be fronted in the environment of an /i/ later in the word. This is an example of anticipatory assimilation because the /u/ takes on the frontness value of the following /i/. At this point [ü] was still an allophone of the phoneme /u/, however, since it occurred only in the context of an /i/ in the next syllable. Next, in period 4, some final vowels in the language were dropped. This leaves the [ü] without the context that originally motivated it. In other words, [u] and [ü] now occur in overlapping contexts, and because the distinction between them matters for the meaning of the word, [ü] has become a phoneme in the language. Finally, in period 5, as Old English was changing to Middle English, the phoneme /ü/ was lost, merging with /i/. This made it possible for [k] to occur before /i/, as it once had in the language. But the original change that caused [k] to become [č] in this context hundreds of years before no longer applied. Thus at this point [k] and [č] occurred in overlapping contexts; namely, both could occur before /i/. Since the distinction between [k] and [č] also mattered for the meaning of the word, the two phones had become separate phonemes in the language. In fact, the words for 'kin' and 'chin' already constituted a minimal pair for these two phonemes.
Inferring phonological change
Say there are two related languages A and B. In A there is a contrast between /t/ and /θ/; in B there isn't. There are two possible histories that could have resulted in this situation, starting from the ancestor language of A and B. What are they?
How can linguists figure out what changes have occurred in the history of a language? Recent changes are not a problem; there may still be older speakers whose speech is a reflection of the period before a change took place. For earlier changes, we sometimes rely on written records, though this presents several problems. First, as we have seen, orthography never does a very good job of representing phonology, especially allophonic differences, and it tends to lag behind, representing earlier pronunciation rather than current pronunciation. Second, some writing systems, such as Chinese characters, which are also used in Japanese, do not represent phonology in any direct way at all. Third, most languages are not written, and languages that are written today were not always written.
For these reasons, written records can never be adequate for a full picture of phonological change. Linguists have developed another technique for inferring the past. If a change has taken place in a particular dialect or language, there are likely to be other related dialects or languages where the change has not taken place. So by examining a set of related dialects or languages, it is sometimes possible to infer how some of them have changed and what the dialect or language that is the ancestor of the whole set was like. Consider the following example from English; the table compares the forms of several words in General American and Received Pronunciation with those in the English of Northern England and Ireland.
| GA, RP | E. of Northern England, Irish E. |
|
| put | /pʊt/ | /pʊt/ |
| look | /lʊk/ | /lʊk/ |
| but | /bʌt/ | /bʊt/ |
| luck | /lʌk/ | /lʊk/ |
We see here (and more examples would make it even more obvious) that the English of Northern England and of Ireland makes no distinction between /ʊ/ and /ʌ/; there is instead a single phoneme pronounced [ʊ]. We know that these dialects (and many others) share a common ancestor dialect with General American and Received Pronunciation. The problem is that from the data here alone, there are two possibilities for the history of these phonemes. Either the ancestor English dialect made a distinction between /ʊ/ and /ʌ/, and this distinction was lost in the English of Northern Ireland and Ireland, or the ancestor dialect did not make the distinction and the distinction emerged in General American and Received Pronunciation. If we look at other dialects, we discover that the distinction is made almost everywhere except in Northern England and Ireland. This means that, if the second alternative is right, the distinction would have to have emerged a long time ago, when all of those other dialects still shared a common ancestor. If the first alternative is right, we would expect the dialects of Northern England and Ireland to be closely related to one another, that is, to constitute a subgroup within English dialects where the distinction was lost.
To figure out which alternative is right, we can look for several other sources of information. We could try to determine from linguistic or other evidence whether the dialects of Northern England and Ireland are closely related. In fact we would discover that they are not very similar, no more similar to each other than either is to RP. Or we could look for evidence from another dialect that we know diverged from the common ancestor of all of these dialects even earlier. Unfortunately this is not very helpful in this case since the evidence is somewhat mixed. Finally we could try to come up with an explanation for how the distinction could emerge, similar to what happened in the case of /č/. The story is too complicated to go into here, but it is possible to see the the split between /ʊ/ and /ʌ/ as beginning with allophonic variation and ending with the present phonemic distinction. This in fact is apparently what happened. That is, it is the dialects of Northern England and Ireland that are more like the ancestor dialect with respect to these vowels and it is the ancestor of the other dialects that changed.
Here is another example. The modern dialects of Japanese, spoken on the main Japanese islands, and Ryukyuan, spoken in the Ryukyu islands of southern Japan, are the descendants of a single language, spoken perhaps 1000 years ago. We can infer what changes have taken place in the different dialects and what the ancestor language looked like by comparing the modern dialects. In the table below are some example words in two of the dialects. We assume that an analysis of the modern dialects has already determined what the phonemes in these dialects are, so phonemic notation is used. The symbol /ɸ/ represents a voiceless bilabial fricative, and long vowels are doubled. Tone patterns are ignored (both dialects use pitch contrastively).
|
|
Standard Japanese | Central Okinawan |
|---|---|---|
| 'body' | /karada/ | /duu/ |
| 'bone' | /hone/ | /ɸuni/ |
| 'branch' | /eda/ | /ida/ |
| 'breath' | /iki/ | /ʔiiči/ |
| 'dance' | /odori/ | /udui/ |
| 'daytime' | /hiru/ | /ɸiru/ |
| 'fog' | /kiri/ | /čiri/ |
| 'grass' | /kusa/ | /kusa/ |
| 'hair' | /ke/ | /kii/ |
| 'man' | /otoko/ | /wikiga/ |
| 'open' | /akete/ | /ʔakiti/ |
| 'organ' | /kimo/ | /čimu/ |
| 'sash' | /obi/ | /ʔubi/ |
| 'shoulder' | /kata/ | /kata/ |
| 'sleeve' | /sode/ | /sudi/ |
| 'south' | /minami/ | /nisi/ |
| 'stomach' | /hara/ | /wata/ |
| 'sun' | /hi/ | /tiida/ |
| 'rain' | /ame/ | /ʔami/ |
| 'rock' | /isi/ | /ʔisi/ |
| 'west' | /nisi/ | /ʔiri/ |
| 'where' | /doko/ | /maa/ |
| 'wine' | /sake/ | /saki/ |
For any pair of related dialects or languages, some words with the same meaning will have arisen from the same form, and others won't. Even for very closely related dialects such as General American and Received Pronunciation, we will find pairs such as /'ɛlə,vetər/ and /lɪft/ (elevator, lift), forms with the same meaning but different origins. When we are interested in phonological change, we should only take into account forms that are obviously related. For the above example, words that we should ignore include the words for 'body', 'man', 'south', 'stomach', 'sun', 'west', and 'where' because the words with these meanings in the two dialects clearly have different origins. On closer examination, we see that the Okinawan word for 'south' is identical to the Japanese word for 'west'. Since these meanings are related, it appears that the origin of the forms is the same, so we can also use this pair for comparison.
Once we have found comparable pairs of words, we need to set up correspondences between pairs of phonemes or combinations of phonemes. When we find differences, we will look more closely to see what changes might have occurred in one or the other dialect. We will focus here only on the phonemes that differ in the two languages and ignore some details such as vowel length in Okinawan. The table below summarizes these. "V" represents any vowel, and "#" represents the beginning of a word.
| Standard Japanese | Central Okinawan |
|---|---|
| /i, e/ | /i/ |
| /o, u/ | /u/ |
| /k/ | /k, č/ |
| /#V/ | /#V, #ʔV/ |
In each of these cases, one dialect has two forms where the other has one. As in the example of English /ʌ/ and /ʊ/, the change is either a merging of two phones into one or a splitting of one phone into two. Let's consider the vowels first. Note first that there are two similar patterns: a high vowel in Okinawan (/u/, /i/) corresponds to that same vowel and a lower vowel in Japanese (/u, o/, /i, e/). Because languages tend to be systematic, we would expect whatever holds for one of these to be true for the other as well.
Let's first consider the possibility that the parent language had only three vowels, /a, i, u/, like Central Okinawan, and a change took place in the ancestor of Standard Japanese, resulting in five vowels, /a, i, e, u, o/. As before, the explanation for the emergence of new phonemes is more complicated than the explanation for the merging of phonemes. As we've seen earlier in this section, new phonemes normally begin with an allophone occurring in some contexts but not others. So by this story, [e] would have first appeared as an allophone of /i/ in some contexts. But what contexts? As you know by now, allophonic variation often involves assimilation, where a phoneme agrees with features of preceding or following phonemes. The relevant context for a vowel could include the preceding or following consonant, or perhaps the vowel in the preceding or following syllable. But given the phonemes of these dialects, it is hard to see how any contexts would have led /i/ to be realized as [e].
What about the alternative, that the parent language had both /i/ and /e/, as in modern Standard Japanese, and that the difference disappeared in the ancestor of Okinawan? Here the story is simpler. For some reason, /e/ in this dialect began to rise, and apparently because there were not so many minimal pairs distinguished only by the difference between /i/ and /e/, /e/ merged with /i/, becoming a single phoneme. The same thing would have happened for /o/ and /u/ in this dialect.
Of course this is still a hypothesis. We could strengthen it with data from another dialect that we know diverged from the parent language of the other two relatively early. Unfortunately I'm unaware of any such data.
Now let's consider the case of /k/ and /č/. There are three examples of /č/ in the Okinawan data. In all cases /č/ appears before /i/. This leads us naturally to the hypothesis that /k/ came to be realized as [č] in Okinawan when it appeared before /i/, a process of palatalization (exactly the sort of change we saw for Old English above). But there is a problem with this hypothesis: in the Okinawan word /ʔakiti/, we have /k/ (that is, [k]) before /i/. Notice, however, that this /i/ in Okinawan corresponds to /e/ in Japanese. That is, in all cases where we have /ki/ in Japanese, we have /či/ in Okinawan. The solution is to propose that the two changes in Okinawan happened in a particular order. First, /k/ came to be realized as [č] when it appeared before /i/. At this point [č] might have been just an allophone of the phoneme /k/, and 'open' would still have been /ʔakete/ (or /akete/) in Okinawan. Then later, /e/ moved and merged with /i/. If the first change had stopped taking place at this time, we would now have /ʔakiti/ in Okinawan. At this point, since both [č] and [k] could appear before /i/ (and affect the meaning of the word), [č] had become a separate phoneme in the language, that is, /č/.
Note how this proposed sequence of events is similar to that postulated for the history of English. In both cases [č] first emerged as an allophone of /k/ in the context of a following /i/ (palatalization). Later another vowel — [ü] in Old English, [e] in Okinawan — came to be pronounced [i], but the old palatalization rule was no longer in effect so words in which /k/ had preceded this other vowel now had [ki]. Since both [či] and [ki] could now occur, and in different words, /č/ and /k/ had become separate phonemes.
4.7 |
Phonology in the wild |
If you've listened carefully to your own pronunciation of English words since you started learning about phonology in this book, you may have noticed that the pronunciation given doesn't correspond to the way you sometimes say the words, that your pronunciation varies with the situation.
In Chapter 1, we already saw that the conventions characterizing a particular dialect can change depending on the context the language is used in. What is appropriate in one context may not be in another. This applies to pronunciation, as well as to vocabulary and grammar.
The dimension we will be concerned with here is sometimes referred to in terms of how "careful" the speech is. The "care" referred is care on the part of the Speaker. To what extent does the Speaker make an effort to accurately produce each of the phonemes and suprasegmental features of the words? To make sense of this idea, we will have to assume that each word in a dialect has a "careful" or "canonical" pronunciation, that is, how the word would sound (or look in a sign language) if produced in isolation or with some emphasis within a sentence and in a relatively formal setting. In general, as the word gets less emphasis and the setting gets more casual, we find a tendency for Speakers to deviate from the careful pronunciation. These deviations are Speaker-oriented; that is, they can all be seen as making the pronunciation easier in one way or another; they are simplifications. Simplification is possible because in the casual situations where it is most common, the Hearer knows the Speaker well and is better able to predict what the Speaker is saying than a stranger would be. In this section we will look at some examples of the simplifications that occur in casual English. We will see that they can often be described in terms of the same sorts of processes we have seen elsewhere in this chapter. Because simplification sometimes result in phones that do not clearly belong to one or another English phoneme, I'll be using the "[]" notation for pronunciations.
Preliminaries
Before we look at the simplifications that happen in English as speech becomes more casual, we need to look at some basic features of English phonology.
First, in English, as in many languages in which stress plays a major role, there are significant differences between stressed and unstressed syllables. Stressed syllables permit all of the possible vowel phonemes, whereas unstressed syllables (in my accent) are mainly limited to /ə/, /ɪ/, and /i/, with /ə/ by far the most common. We can see these differences most clearly when we look at how the pronunciation of a syllable changes when it becomes stressed or unstressed. Consider the second syllables in the following related pairs of words.
- melody, melodic
- repeat, repetition
In melodic the second syllable is stressed, and the vowel is pronounced /ɑ/. In melody it is unstressed, and the vowel is pronounced /ə/. In the second pair, the second vowel is /i/ when it's stressed and /ə/ when it's unstressed.
Like all languages, English has phonotactic constraints on what sequences of vowels and consonants can occur. As in many languages, English phonotactics interacts with morphology, a topic that we will begin looking at in Chapter 7. For now, it is enough to know that English has words like dog and believe that consist of just one "morpheme". That is, you can't break them down into smaller meaningful units. And English has words like dogs and believed consisting of more than one morpheme: dog + -s and believe + -ed. The reason this matters for phonotactics is that the constraints are different for words consisting of one and words consisting of more than one morpheme. Words with just one morpheme normally do not contain sequences of more than one vowel. But words ending in the morpheme -ing may have such sequences.
- playing, trying, showing
Similarly the limits on possible sequences of consonants within one-morpheme words are relaxed in words ending in morphemes such as -s and -ed
- bumped, asked, thanked, acts, fifths, sixths
These words end in sequences of three or four consonants that do not occur in words with one morpheme: /mpt/, /skt/, /ŋkt/, /kts/, /fθs/, /ksθs/.
General simplifications
As we have just seen, phonotactics is to some extent a matter of degree. There are constraints that apply to English words of one morpheme, but these are relaxed in words of more than one morpheme, which may result in sequences of vowels or consonants that would otherwise seem odd to English speakers. Consider first cases where the result is a sequence of more than one vowel, as in the words in 3 above. While these may be pronounced as such in careful speech, in casual speech, they may become a single vowel. This is especially likely when the -ing suffix would have the pronunciation [ən] as opposed to [ɪŋ]. So these three words could be pronounced [plen], [trayn], and [šon] in casual speech. In each case the /ə/ has been deleted to simplify the pronunciation.
The same thing can happen with sequences of consonants that are "odd" for English, as in 4 above. In some accents, these words are never pronounced with the sequence of three or four consonants that is implied by the spelling. In others, such as my accent, they are pronounced this way in careful speech but lose one of the consonants in casual speech, especially when the next word also begins with a consonant. So acts becomes [æks], thanked becomes [θæŋt], and fifths becomes [fɪθs].
Other possible simplifications may occur across the boundaries between words. Consider what happens when an alveolar consonant ends up before a /y/, as in two places in the following sentence.
- Write your name on this yellow sheet.
Speaking carefully, most people would pronounce the two parts shown in bold as [ty] and [sy]. But when we speed up and allow ourselves to simplify, these may become [č] and [š]. This is an example of assimilation. The alveolar and palatal consonants combine to yield single consonants that are at the postalveolar place of articulation, which is in between the original places. Note, however, that this process must somehow be constrained. For example, in my accent the [ty] of that yellow sheet would never become [č], no matter how casually I'm speaking (instead the [t] would become a glottal stop, [ʔ]). The constraints appear to be quite complicated, and I won't have more to say about them, except that they are clearly related to the stress of the words on either side of the boundary.
A third tendency is for the appearance of the same consonant twice with an unstressed vowel in between to be simplified through the deletion of the vowel and the reduction to a single consonant. Here are some examples, with the careful pronunciation first, then the simplified pronunciation.
- probably: ['prɑbəbli, 'prɑbli]
- necessary: ['nɛsə,sɛri, 'nɛ,sɛri]
- terrorism: ['tɛrə,rɪzəm, 'tɛ,rɪzəm]
Simplifications specific to particular words
We have seen that there are simplifications that can happen in English speech to particular sequences of phonemes, independent of what word they occur in. Most of the familiar simplifications that characterize English casual speech, however, apply to particular words and not to others.
One possibility is a word that for whatever reason has a sequence of phonemes within it that is unusual for English. A good example is the word sandwich. In some accents, such as mine, this has the careful pronunciation ['sændwɪč]. But the sequence [ndw] in the middle of this word is very rare in English, and for many people the word has the alternate pronunciation ['sæmwɪč] in casual speech. (Of course for many other people this may be the only pronunciation of this word.) Note, however, that this tendency seems to be confined to this word. At least in my accent, it is not possible to simplify the sequence [ndw] similarly in a word such as bandwidth.
The frequency of a word has a clear effect on its tendency to be simplified. In 6 above we saw a simplified pronunciation for the word probably, but because this word is common, this may also represent the careful pronunciation for some speakers. In fact the word can undergo further simplifications: to ['prɑli] and even [pray].
Words that are not very informative also have a strong tendency to be simplified, probably because they are more predictable from the linguistic context than words that convey more information. Since many such words in English are also very common, they appear more often in their simplified form than in their canonical, careful pronunciation, which is normally only appropriate when they are stressed. Here is a partial list of these words, showing for each at least two pronunciations, ranging from the canonical, stressed, careful pronunciation to the most unstressed and casual.
- you: [yu, yə]
- he: [hi, i]
- him: [hɪm, ɪm]
- them: [ðɛm, əm]
- our: [awr, ɑr]
- of: [ʌv, əv, ə]
- to: [tu, tə]
- for: [fɔr, fər]
- out: [awt, at]
- am: [æm, əm, m]
- is: [ɪz, əz, z, s]
- are: [ɑr, ər, ə]
- have: [hæv, əv, v]
- did: [dɪd, dəd, d]
- will: [wɪl, wəl, əl, l]
- can: [kæn, kən]
- would: [wʊd, əd, d]
- while: [wayl, wal]
- because: [bɪ'kɔz, bɪ'kʌz, kʌz, kəz]
- how: [haw, ha]
Notice that many of these variants are predictable if we recall that unstressed vowels tend to be pronounced as [ə]. But not all vowels get reduced to [ə]. In some words the diphthongs [aw] and (less often) [ay] can lose their second element, becoming simply [a] (or [ɑ] before [r]). The pronunciation of did as [d] also agrees with the general tendency for a repeated consonant to merge into a single consonant. However, in other words, an initial or final consonant is dropped in a way that would not be predictable from the general tendencies discussed above. Thus it appears that some of these simplifications are conventional.
Finally, frequently occurring sequences of words are often simplified, especially when they consist of words from the group just illustrated. Some of these simplifications are so frequent that they represent the careful pronunciation, and they have even entered English orthography as contractions such as it's, they're, doesn't, and I'd. Most of these pronunciations are predictable from the simplified forms we have already encountered, but a few, such as don't (from [du nɑt]) and won't (from [wɪl nɑt]) are not. For some there are multiple pronunciations, varying in how casual and unstressed they sound. Here are a few of these.
- I'm: [aym, am, əm]
- they're: [ðɛr, ðər]
- we're: [wɪr, wər]
- wouldn't: ['wʊdn̩t, 'wʊdn̩]
Also very common are these combinations with have and to as the second word.
- would (should, could) have: ['wʊɾə]
- going to: ['gənə]
- got to: [gɑɾə]
- want to: [wɑnə]
- have to: [hæftə]
- has to: [hæstə]
- supposed to: ['spostə]
- trying to: ['traynə, 'tranə]
Notice how in 35 the two [t]s merge into one, pronounced as the tap [ɾ], and how they disappear altogether in 36.
Finally, let's see how some frequent sequences of three or more words are pronounced in very casual speech (in my accent).
- You wouldn't have thought so. [yə,wʊdn̩ə 'θɔt ,so]
- What did you think? [,wʌǰə 'θɪŋk]
- How has he been? [,hazi 'bɪn]
- I am going to look. [,amənə 'lʊk]
- I don't know. [,aɾə 'no]
Let's summarize what we found for simplified speech in English. First, how likely a word or sequence of words is to be simplified depends on at least on these factors.
- How frequent the form is
- How little information the form carries
- How casual the situation is
Second, the simplifications that occur involve assimilation; the reduction of vowels, often to [ə]; the merging of sequences of the same consonant; the deletion of [ə] and some initial or final consonants. Many of these processes are general processes in the language. In some cases, however, the simplifications are conventions associated with particular words and must be learned separately.
4.8 |
Problems |
4.8.1 Phonetic contexts and assimilation
- English vowels in most dialects have various possible degrees of length.
In the following words, relatively long variants of the vowels are indicated
with a following [:].
Based on these examples, say what the phonetic context is for the long allophone of English vowels.
- hat [hæt]
- had [hæ:d]
- gas [gæs]
- jazz [jæ:z]
- mate [met]
- made [me:d]
- roast [rost]
- rose [ro:z]
- hoop [hup]
- tube [tu:b]
- buck [bʌk]
- bug [bʌ:g]
(This is not part of the answer, just how you might get to the answer.) Looking at the whole list of words, we can see that both the long and the short vowels occur between consonants in all of the words. Since we're looking for complementary (non-overlapping) distributions, it can't have anything to do with occurring before or after consonants or vowels. So it must have something to do with what kind of consonant occurs before or after (or both) for the two allophones. Looking at the context before the vowels first, we notice in the first two wrods that exactly the same consonant, [h], can occur before the short and the long allophones of /æ/. The same thing is true for /e/ since both allophones can occur after [m]. Obviously what comes before the vowels can't be complementary because the same consonsants can occur with both allophones. So the relevant context must be after the vowels. Let's see which consonants occur after the short allophones: [t, s, p, k]. And which after the long allophones: [d, z, b, g]. No consonants are shared in the two sets; that is, there's no overlap. So we're on the right track. But we need to generalize about the sets, that is, say what it is that all of the consonants in each set have in common. All of those in the first set are voiceless, while all of those in the second set are voiced.The long allophone occurs before voiced consonants. -
The Japanese phoneme /s/ has two allophones: [s] and [š]. Based on the following
words, say what the phonetic contexts for the two allophones are.
- [saya] 'pod'
- [kasa] 'umbrella'
- [senkyo] 'election'
- [mise] 'store'
- [sono] 'that'
- [heso] 'navel'
- [suši] 'sushi'
- [hanasu] 'speak'
- [šiku] 'spread'
- [šima] 'island'
- [šite] 'doing'
- [kuši] 'skewer'
- [sašimi] 'sashimi'
- [meši] 'rice'
- [sasemašita] 'caused'
[š] occurs before [i]; [s] occurs elsewhere (before other vowels). -
In Modern English, as you know, the fricatives [f, v, θ, ð, s, z] are all
separate phonemes.
But in Old English, although all of these phones occurred, they made
up only three phonemes, each with a voiceless and a voiced allophone:
[f, v], [s, z], [θ, ð].
The voiceless allophones are the more general (default) forms.
Given the following words, (i) say what the phonetic context for the
voiced allophones is, and (ii) say how the change from voiceless to
voiced in this context is an example of assimilation.
Hint: the context includes both what precedes and what follows the
consonants.
([:] indicates vowel length, and phonetic details of vowels are not
indicated because they are irrelevant.)
- [fæst] 'firm'
- [full] 'very'
- [æfter] 'after'
- [klif] 'cliff'
- [heəvon] 'sky'
- [seva] 'mind'
- [hævde] 'had'
- [hweərvan] 'return'
- [æ:vre] 'always'
- [sunu] 'son'
- [la:st] 'track'
- [hu:s] 'house'
- [hors] 'horse'
- [ræ:zan] 'to attack'
- [i:zern] 'iron'
- [ræ:zde] 'attacked'
- [bizgu] 'occupation'
- [θæ:əw] 'custom'
- [wraθ] 'angry'
- [so:θ] 'true'
- [θiyeθ] 'receives'
- [kweðan] 'to say'
- [swi:ðre] 'right hand'
- [wraðu] 'support'
- [furðor] 'further'
(This isn't part of the answer.) The fact that I know assimilation is involved can help me with the first part. Since the allophones in each pair differ only in voicing and since assimilation means changing one allophone into another to make it more like its neighbors, this must mean that the voicing of the neighbors of these consonants has something to do with the complementary distribution that we're looking for. So let's start with what comes before. One thing that seems to be true is that the voiceless allophones can occur at the beginnings and ends of words whereas the voiced allophones can't occur in either of these places, but that still doesn't qualify as complementary because the voiceless allophones don't have to occur at the beginnings or ends; they can also occur in the middle of words. So we have to show how the allophone pairs fail to overlap when they occur in the middle of words. Let's start with what comes before. Clearly both the voiceless and voiced allophones can follow both vowels and consonants. so that doesn't help. And both the voiceless and voiced allophones can precede both vowels and consonants (though not necessarily in the middle of words). But remember this should have something to do whether things in the context are voiced or voiceless. Remember that vowels are voiced. Let's look at the voiceless allophones first. In the words we have, these are always preceded by voiced phones (unless they appear at the beginning of a word). And they can be followed by either voiced or voiceless phones. What about the voiced allophones? In all words these are both preceded by and followed by voiced phones. Now let's check to see whether the voiceless allophones are never both preceded by and followed by voiced phones. They're not. So the easiest way to state this is to start with the more specific allophones, that is, the voiced ones, and then treat the more general ones, the voiceless ones, as the "elsewhere" case.(i) The voiced allophones ([z], [v], [ð]) occur between two voiced sounds. (ii) This is assimilation because the fricative is agreeing with the sounds around it in voicing (it is taking on the voicing of its neighbors). -
The following words are from one dialect of Tzeltal.
['b] is a voiced glottalized bilabial stop, roughly a [b]
accompanied by a glottal stop.
Recall that [t'], [p'], and [k'] represent voiceless
ejective (glottalized) stops.
- [bi] 'what'
- [bu t'il] 'as'
- [hba] 'myself'
- [šbahth] 'goes'
- [sba] 'him/herself'
- [t'uhbil] 'beautiful'
- [ilbil] 'seen'
- [tahb] 'twenty'
- [ti'bal] 'meat'
- [ho'bel] 'San Cristóbal' (a city)
- [ma'ba] 'not'
- [ča'b] 'honey'
- [haye'b] 'how many'
- [tuth] 'small'
- [tulel] 'to harvest'
- [htath] 'my father'
- [čitam] 'pig'
- [path] 'back'
- [nahth] 'tall'
- [sith] 'fruit'
- [t'ut'] 'greedy'
- [t'anal] 'heaped'
- [t'ulel] 'to pour'
- [yut'il] 'inside'
- [naht'] 'long'
- [path] 'back'
- [pohph] 'mat'
- [spuy] 'his snail'
- [hpikh] '8000'
- [k'opoh] 'spoke'
- [sp'uy] 'squashed'
- [p'ihp'inel] 'to spread'
- [snop'] 'seized'
- [lap'ap'] 'sticky'
- [hp'itp'on] 'throbbing'
- The Tzeltal phoneme /b/ has two allophones, [b] and ['b].
Using the words above, which are representative of the contexts in which the
allophones occur, say what the complementary distribution of the allophones is.
['b] occurs after vowels; [b] occurs elsewhere.
- The Tzeltal phoneme /t/ has two allophones, [t] and [th]. Using the
words above, which are representative of the contexts in which the allophones occur,
say what the complementary distribution of the allophones is.
[th] occurs at the ends of words; [t] occurs elsewhere.
- Recall that the Spanish phonemes /b/ and /g/ each have two allophones, stops ([b] and [g]) and approximants ([β] and γ) and that the stops are used when the consonant begins a word after a pause. But they are also used when these consonants follow a nasal consonant. In fact if we look at a lot of Spanish words in context, we see that the only nasal consonant that occurs before /b/ is [m], and the only nasal consonant that occurs before /g/ is [ŋ]. In other words these sequences are possible: [mb], [ŋg], and these are not: [mβ], [nb], [ng], [nγ], [ŋγ]. Some words ending in nasals even change their pronunciation to maintain these constraints. So consider the words un and con, which normally end in a dental nasal [n̪]. When they are followed by /b/ or /g/, however, they take the form of [m] or [ŋ], for example, un vaso [um'baso] 'a glass', con gusto [koŋ'gusto] 'with pleasure'. Explain what is going on, that is, why the nasal consonant changes and why /b/ and /g/ are not realized as approximants after nasals. Your explanation should be in terms of assimilation.
4.8.2 Distribution of phones
-
In addition to the voiced stops /b/, /d/, and /g/, the voiced
fricative /z/, and the nasals
/m/, /n/, and /ŋ/, Lingala has a set of prenasalized
voiced stops and fricatives, that is, stops that begin with nasalization.
I'll write them with a superscript nasal consonant symbol preceding
the stop symbol, for example, /mb/ for the
voiced bilabial stop beginning with nasalization and bilabial closure ([m]).
The prenasalized stops that occur in all dialects of Lingala are
/mb/,
/nd/,
/nz/,
and /ŋg/.
- Say why you think
these are the only prenasalized stops and fricatives that
occur and not, for example, /mz/ or /ŋd/
or /nb/.
The prenasalized stops and fricatives that occur have the same place of articulation for the nasal part and the stop or fricative part. This is easier to pronounce than a combination with different places of articulation, such as /mz/ (bilabial + alveolar). -
Given the following words, say how you know that
(i) [b] and [mb] belong to separate phonemes,
(ii) [m] and [mb] belong to separate phonemes,
(iii) [n] and [nd] belong to separate phonemes,
(iv) [g] and [ŋg] belong to separate phonemes.
Recall that the best way to establish that two phones belong to
separate phonemes is to find a minimal pair for them.
([´] over a vowel marks a high tone; low tone is unmarked.)
- [kozimba] 'to trick'
- [mbáŋgu] 'fast'
- [béŋga] 'call!'
- [gúmbá] 'fold!'
- [kozima] 'to be extinguished'
- [núka] 'gather'
- [mbéŋga] 'vocation'
- [ndúka] 'dam'
- [ndáko] 'house'
- [koŋgala] 'to be wild'
- [ŋgúmbá] 'spleen'
(i) [béŋga] and [mbéŋga] are a minimal pair for [b] and [mb].
(ii) [kozima] and [kozimba] are a minimal pair for [m] and [mb].
(iii) [núka] and [ndúka] are a minimal pair for [n] and [nd].
(iv) [gúmbá] and [ŋgúmbá] are a minimal pair for [g] and [ŋg].
- Say why you think
these are the only prenasalized stops and fricatives that
occur and not, for example, /mz/ or /ŋd/
or /nb/.
- Old English had both short and long low front vowels, [æ]
and [æ:].
From the following examples, say how you can know that these two phones
belong to different phonemes.
- [sæ:] 'sea'
- [θæ:r] 'there'
- [æ:t] 'food'
- [mæ:st] 'most'
- [græ:y] 'gray'
- [dræ:van] 'to drive'
- [klæ:ne] 'clean'
- [bæk] 'back'
- [æt] 'at'
- [wæter] 'water'
- [fæstan] 'fasten'
- [mæst] 'mast'
- [næyl] 'nail'
- [hwæt] 'what'
There are two minimal pairs for [æ] and [æ:]: [æt] / [æ:t] and [mæst] / [mæ:st] - In some accents of southeastern England, the tense (long) vowels include
/ʊu/, /
u:/ (a long rounded, high, central vowel), and /ʌu/. From the following examples, say how you know these are separate phonemes in this accent. Note: they do not correspond directly to phonemes in other accents such as General American.- moan [mʊun]
- tow [tʊu]
- nose [nʊuz]
- sole [sʊul]
- mown [mʌun]
- soul [sʌul]
- knows [nʌuz]
- toe [tʌu]
- news [n
u:z] - moon [m
u:n] - two [t
u:] - soon [s
u:n]
To show that the three phones are separate phonemes, we need to find a minimal pair (or near minimal pair) for each of the three possible pairs. But a minimal triple will also work because it's actually three minimal pairs. There are two minimal triples among the words: moan / mown / moon and tow / toe / two. - In sign languages the main dimensions along which syllables differ
are handshape, location (the place on the body or in space where the sign
is made), movement (the motion of the articulators in space), and
orientation (the direction that the palm "points"). Given the following
ASL signs, say how you know that location and movement are
contrastive dimensions in ASL.
'airplane' 'dry' 'fly (airplane)' 'hamburger' 'massage' 'piano' 'summer' 'worthless' To show that location and movement are contrastive, we need a minimal pair (or near minimal pair) for each. For location, the signs for 'dry' and 'summer' are a minimal pair; the two signs are the same except that one is produced near the forehead, the other near the bottom of the face. For movement, the signs for 'airplane' and 'fly' are a minimal pair; the two signs are the same except that one uses two forward movements, the other uses one. -
Below are some words from Argentine Spanish containing the phones [s]
and [h]. (Each has a different meaning, but the meanings are left off
because they might make it easy for students who know Spanish.)
Syllable boundaries are marked with a space, and [x] represents a
voiceless velar fricative.
Based on these words only, are these two sounds in complementary
or overlapping distribution in the language?
If the distributions are complementary, say what the contexts for each phone are.
If the distributions are overlapping, say how you know.
(Hint: [h] is the more restricted phone.)
English examples:- [ph] (aspirated, voiceless bilabial stop), [p] — complementary, [ph]: at the beginning of a stressed syllable, [p] elsewhere
- [s], [š] — overlapping, sip/ship is a minimal pair
- [sa 'lar]
- ['ka sah]
- [soy]
- ['se so]
- ['syen]
- ['swer te]
- ['swa reh]
- [gon 'sa leh]
- [dye si 'sye te]
- [rre 'swel to]
- ['xwi syo]
- [xweh]
- ['ka xah]
- ['fyeh tah]
- ['xeh to]
- [pah]
- [suh]
Complementary distribution: [h] occurs at the ends of syllables, [s] elsewhere. (In fact [h] is an allophone of /s/ in this dialect and many other dialects of Spanish.) -
In Amharic, consonants can be simple, for example, [t] and [m], or long,
for example, [tt] and [mm].
Given the following words, say whether consonant length is a contrastive
dimension in Amharic, and explain how you know.
- [yɪmɛtal] 'he hits'
- [mɛtta] 'he hit'
- [mɛla] 'scheme'
- [tɛdɛrrɛgɛ] 'it was done'
- [bɛrr] 'door'
- [nɛgɛ] 'tomorrow'
- [mɛlla] 'it got full'
- [nɛgga] 'it dawned'
- [yɪmmɛttal] 'he got hit'
- [zɛr] 'seed'
- [k'ɛllɛlɛ] 'it got easy'
Consonant length is a contrastive dimension. There is a minimal pair for consonant length, [mɛla] / [mɛlla]. (And there are two near minimal pairs, [yɪmɛtal] / [yɪmmɛttal] and [nɛgɛ] / [nɛgga].) -
Amharic /b/ has two allophones, [b] and [β] (a voiced bilabial fricative).
Given the following words, which are representative of words containing
this phoneme, say what the complementary distribution of these allophones
is. (Remember from the last problem that consonant length is contrastive in Amharic.)
- [laβ] 'sweat'
- [rɛhaβ] 'hunger'
- [nɛβɪr] 'leopard'
- [nɛbbɛre] 'was'
- [bɪrd] 'cold'
- [bal] 'husband'
- [bɛlla] 'he (it) ate'
- [tɛβɛlla] 'he (it) was eaten'
- [kɪβɪr] 'honor'
- [tɛβabbɛru] 'they were united'
- [aβro] 'together'
- [gɛβs] 'barley'
- [wɪβɛt] 'beauty'
- [tɛsɛbbɛrɛbbɛt] 'it was broken by it'
- [kɛβt] 'livestock'
- [t'ɪβɛβ] 'wisdom'
- [t'ɛbbaβ] 'narrow'
- [ambɛssa] 'lion'
- [arba] 'forty'
- [albɛlam] 'I don't eat'
[β] occurs after vowels unless it is long; otherwise [b] occurs. - In Tzeltal /t/ (with the context-sensitive allophones [t] and [th]) and /t'/ ([t']) are separate phonemes.
Say how you can know this from the words in problem 4 in 4.8.1 above.
Minimal pair: [tulel] (o), [t'ulel] (w).
- In Tzeltal /p/ (with the context-sensitive allophones [p] and [ph]) and /p'/ ([p']) are separate phonemes.
Say how you can know this from the words in problem 4 in 4.8.1 above.
Minimal pair: [spuy] (ab), [sp'uy] (ae).